
概念定义
-
串:即字符串(String)是由零个或多个字符组成的有限序列。
-
串的长度:串中字符的个数 n,n=0 时的串称为空串。
-
子串:串中任意个连续的字符组成的子序列。
-
主串:包含子串的串。
-
字符在主串中的位置:字符在串中的序号。(注意:空格也是一个字符)
-
子串在主串中的位置:子串的第一个字符在主串中的位置 。
串的基本操作
-
StrAssign(&T, chars):赋值操作。把串 T 赋值为 chars。 -
StrCopy(&T, S):复制操作。由串 S 复制得到串 T。 -
StrEmpty(S):判空操作。若 S 为空串,则返回 TRUE,否则返回 FALSE。 -
StrLength(S):求串长。返回串 S 中元素的个数。 -
ClearString(&S):清空操作。将 S 清为空串。 -
DestroyString(&S):销毁串。将串 S 销毁(回收存储空间)。 -
Concat(&T, S1, S2):串联接。用 T 返回由 S1 和 S2 联接而成的新串 。 -
SubString(&Sub, S, pos, len):求子串。用 Sub 返回串 S 的第 pos 个字符起长度为 len 的子串。 -
Index(S, T):定位操作。若主串 S 中存在与串 T 值相同的子串,则返回它在主串 S 中第一次出现的位置;否则函数值为 0。 -
StrCompare(S, T):比较操作。若 S>T,则返回值>0;若 S=T,则返回值=0;若 S<T,则返回值<0。
-
strcpy(s1, s2);复制字符串 s2 到字符串 s1。 -
strcat(s1, s2);连接字符串 s2 到字符串 s1 的末尾。 -
strlen(s1);返回字符串 s1 的长度。 -
strcmp(s1, s2);如果 s1 和 s2 是相同的,则返回 0;如果 s1<s2 则返回小于 0;如果 s1>s2 则返回大于 0。 -
strchr(s1, ch);返回一个指针,指向字符串 s1 中字符 ch 的第一次出现的位置。 -
strstr(s1, s2);返回一个指针,指向字符串 s1 中字符串 s2 的第一次出现的位置。 -
strlwr(s1);返回原字符串的小写形式。 -
strupr(s1);返回原字符串的大写形式。
KMP
i不变,j变到第几位就是next数组
改进后判断next的那个与当前是否相同,不同则匹配失败为1
树
树的属性和性质
属性
结点的度:有几个孩子(分支)
树的度:各结点的度的最大值
性质
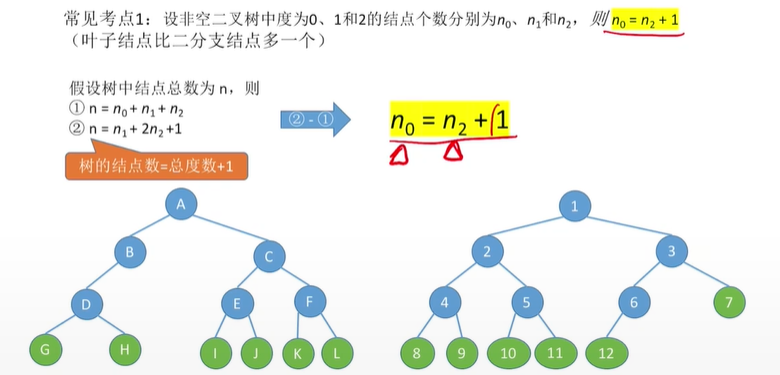
1)结点数=总度数+1
2)度为m的树、m叉树的区别 度为m的树: ① 任意结点的度<=m(最多m个孩子) ② 至少有一个结点度=m(有m个孩子) ③ 一定是非空树,至少有m+1个结点
m叉树: ① 任意结点的度<=m(最多m个孩子) ② 允许所有结点的度都<m ③ 可以是空树
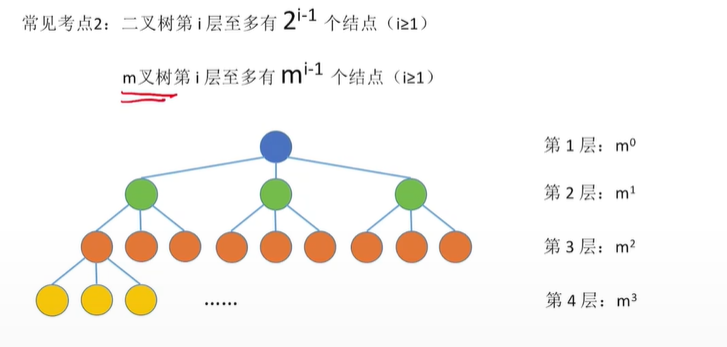
3)度为m的树第 i 层至多有m^(i-1)个结点(i>=1) m叉树第 i 层至多有m^(i-1)个结点(i>=1)
二叉树
定义
每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。
五种基本形态
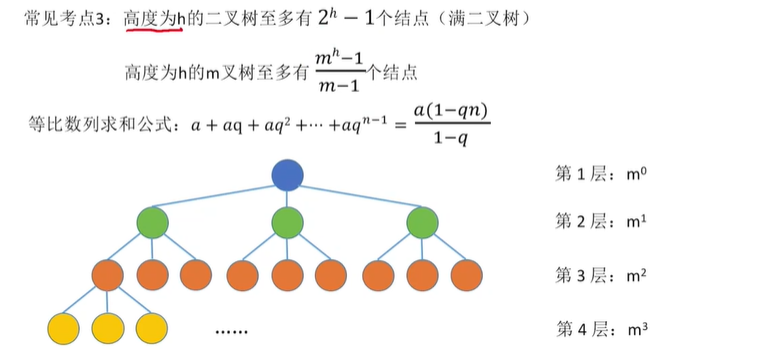
满二叉树
完全二叉树
二叉排序树
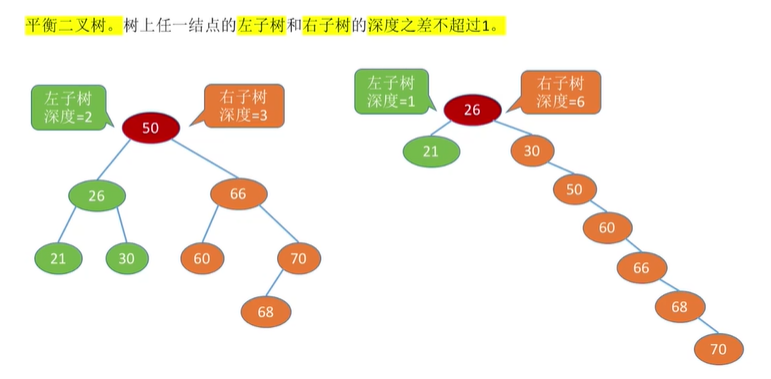
平衡二叉树
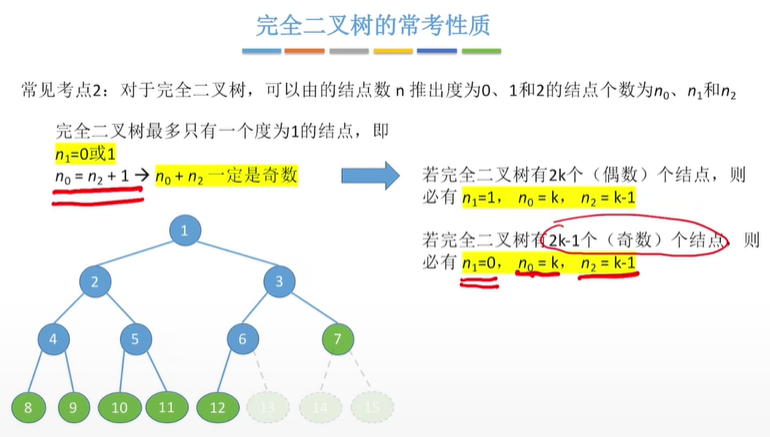
二叉树性质
n0=n2+1

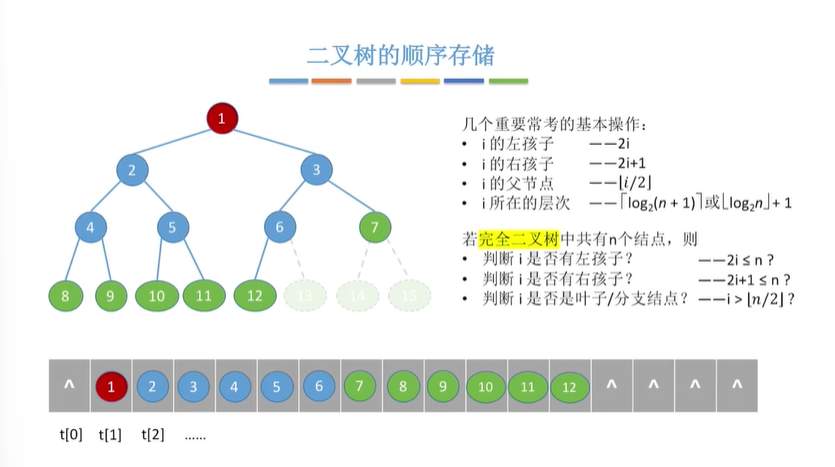
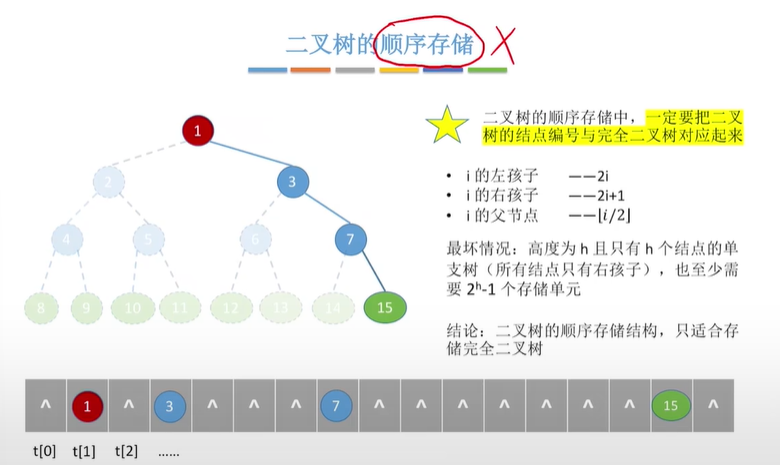
二叉树的存储结构
顺序存储
struct TreeNode{
ElemType value;//结点中的数据元素
bool isEmpty;//节点是否为空
}
TreeNode t[MaxSize];

链式存储
struct ElemType{
int value;
};
typedef struct BiTNode{
ElemType data;
struct BiTNode *lchild,*rchile;//左右孩子指针
}BiTNode,*BiTree;
//定义一棵空树
BiTree root=NULL;
//插入根节点
root=(BiTree)malloc(sizeof(BiTNode));
root->data={1};
root->lchild=NULL;
root-<rchile=NULL;
//插入新节点
BiTNode *p=(BiTNode*)malloc(sizeof(BiTNode));
p->data={2};
p->lchild=NULL;
p->rchild=NULL;
root->lchild=p;//做为根结点的左孩子二叉树的遍历
先序遍历
//先序遍历
void PreOrder(Tree &t){
if (t != NULL)
{
// visit(T);
cout << t->data << " ";
PreOrder(t->lchild);
PreOrder(t->rchild);
}
}中序遍历
// 中序遍历
void MidOrder(Tree &t)
{
if (t != NULL)
{
MidOrder(t->lchild);
// visit(T);
cout << t->data << " ";
MidOrder(t->rchild);
}
}后序遍历
// 后序遍历
void PostOrder(Tree &t)
{
if (t != NULL)
{
PostOrder(t->lchild);
PostOrder(t->rchild);
// visit(T);
cout << t->data << " ";
}
}层序遍历

// 层序遍历
void ceng(Tree &t){
queue<Node*> tq;
Node *temp;
tq.push(t);
while(tq.empty()){
temp = tq.front();
tq.pop();
if (temp->lchild!=NULL)
tq.push(temp->lchild);
if (temp->rchild != NULL)
tq.push(temp->rchild);
}
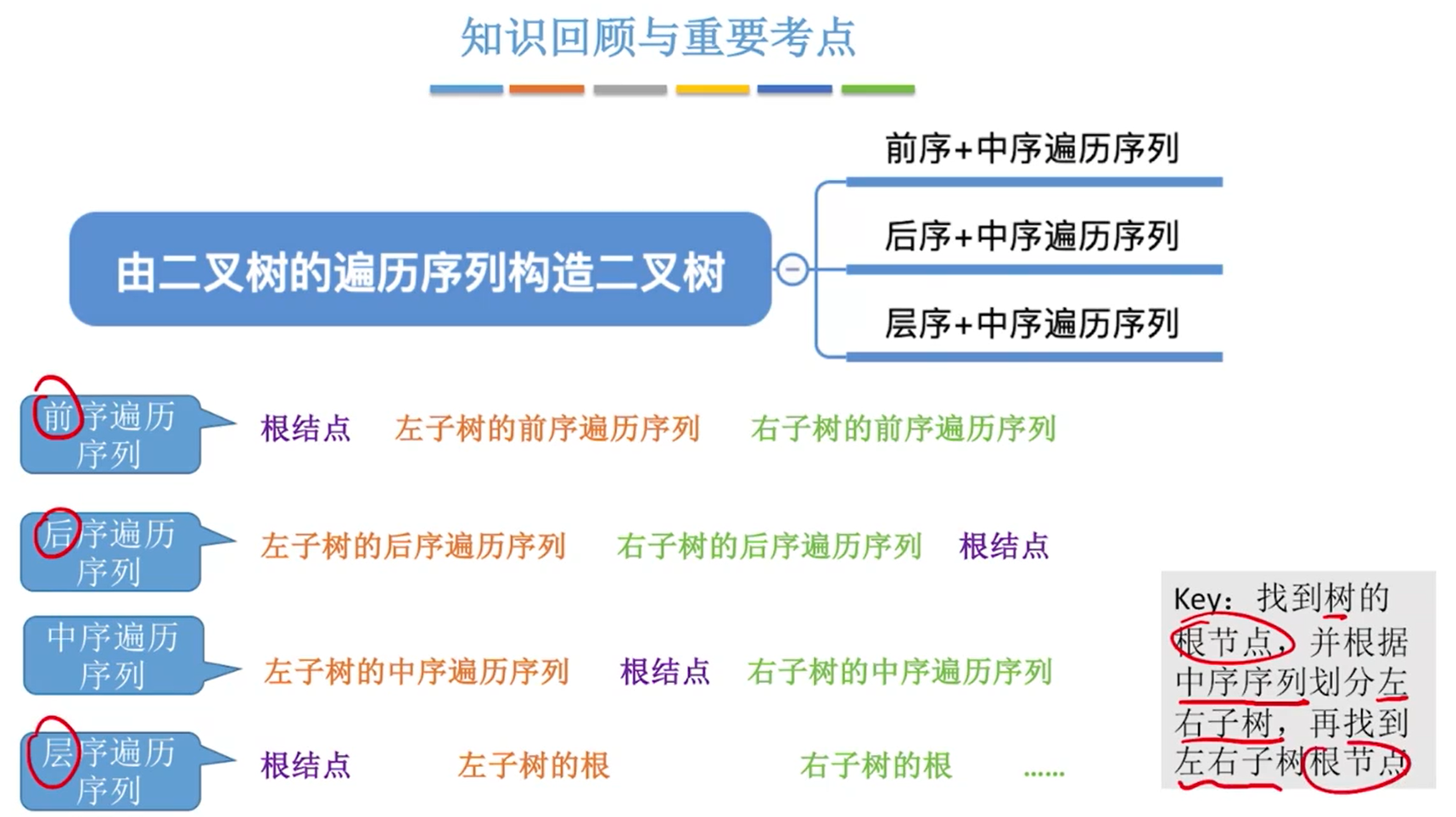
}由遍历序列构造二叉树
一定都需要有中序序列

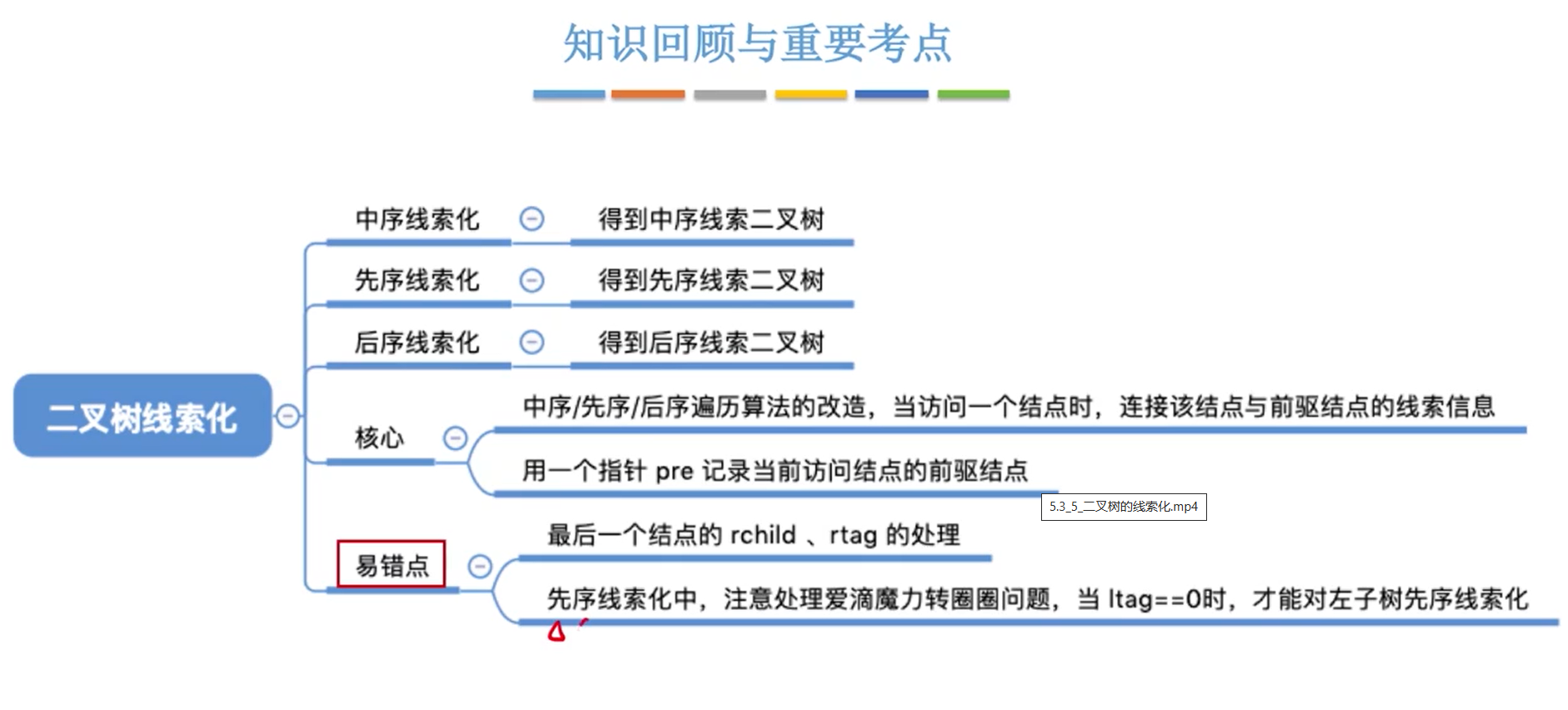
线索二叉树
建立
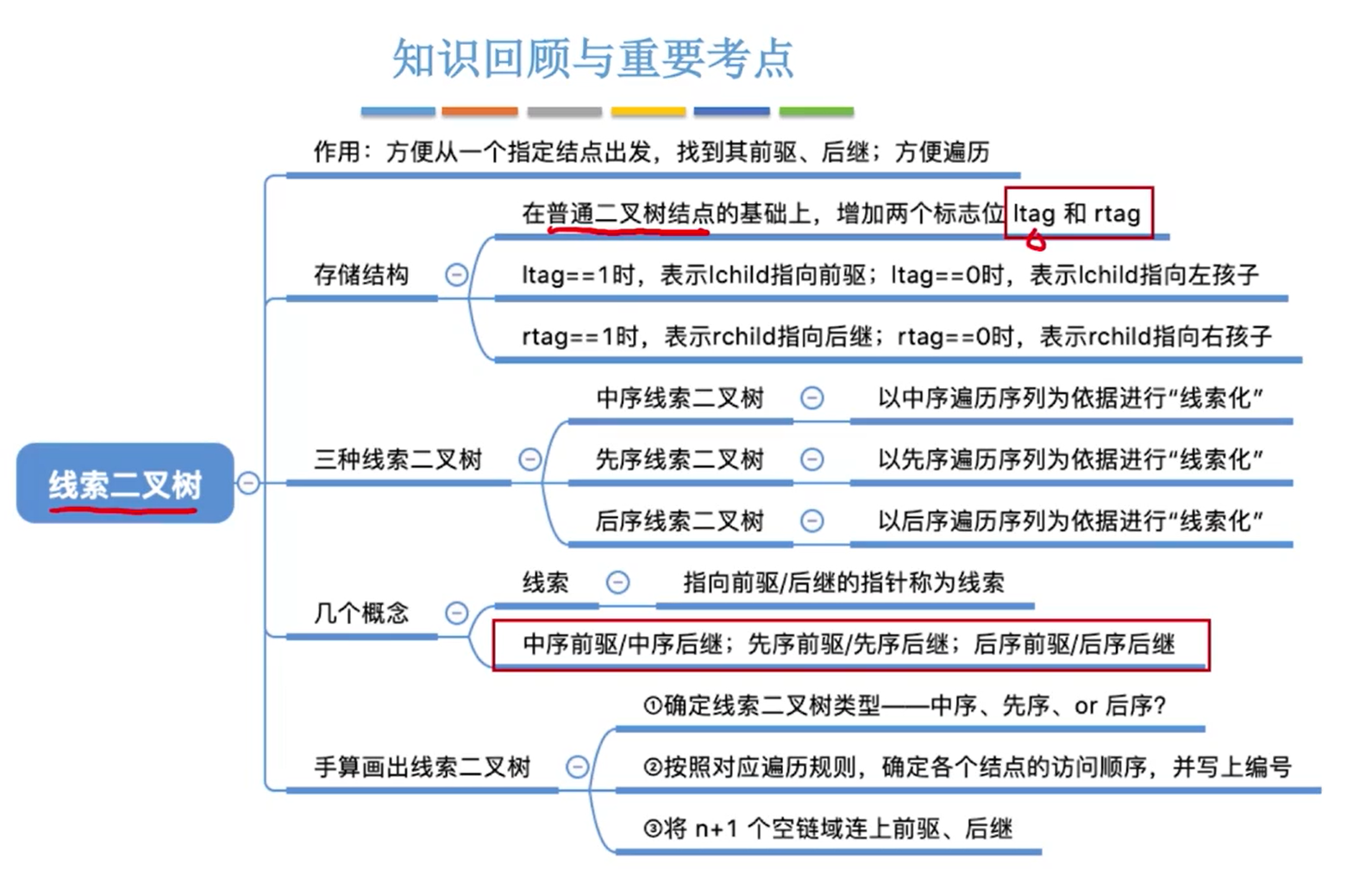
重点:建立先序线索二叉树的时候要先判断左子树是否已经线索化再递归遍历,否则就会遍历会前驱然后反复循环
要在程序中处理最后一个节点,如果最后一个节点的右孩子为空则
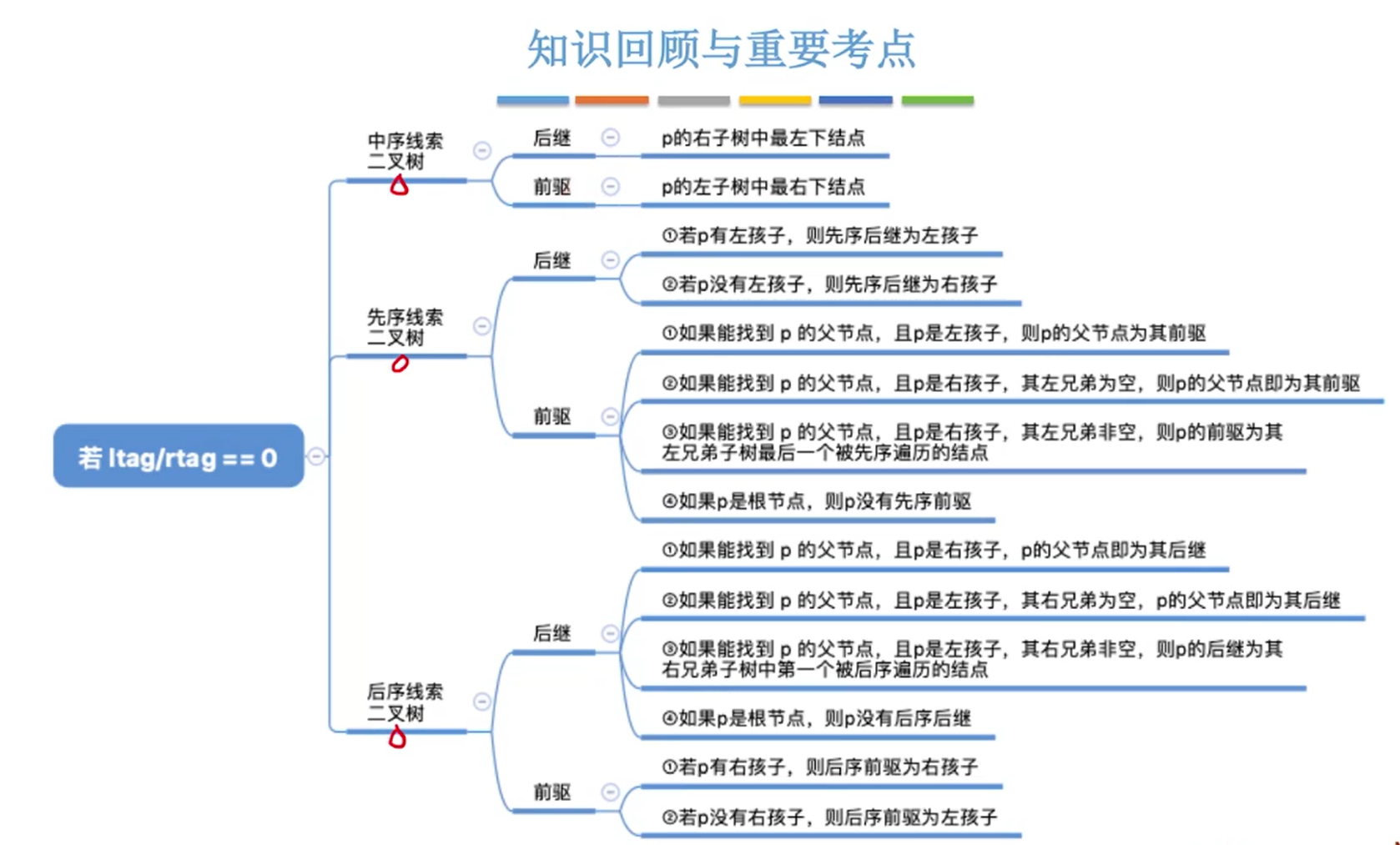
找前驱后继
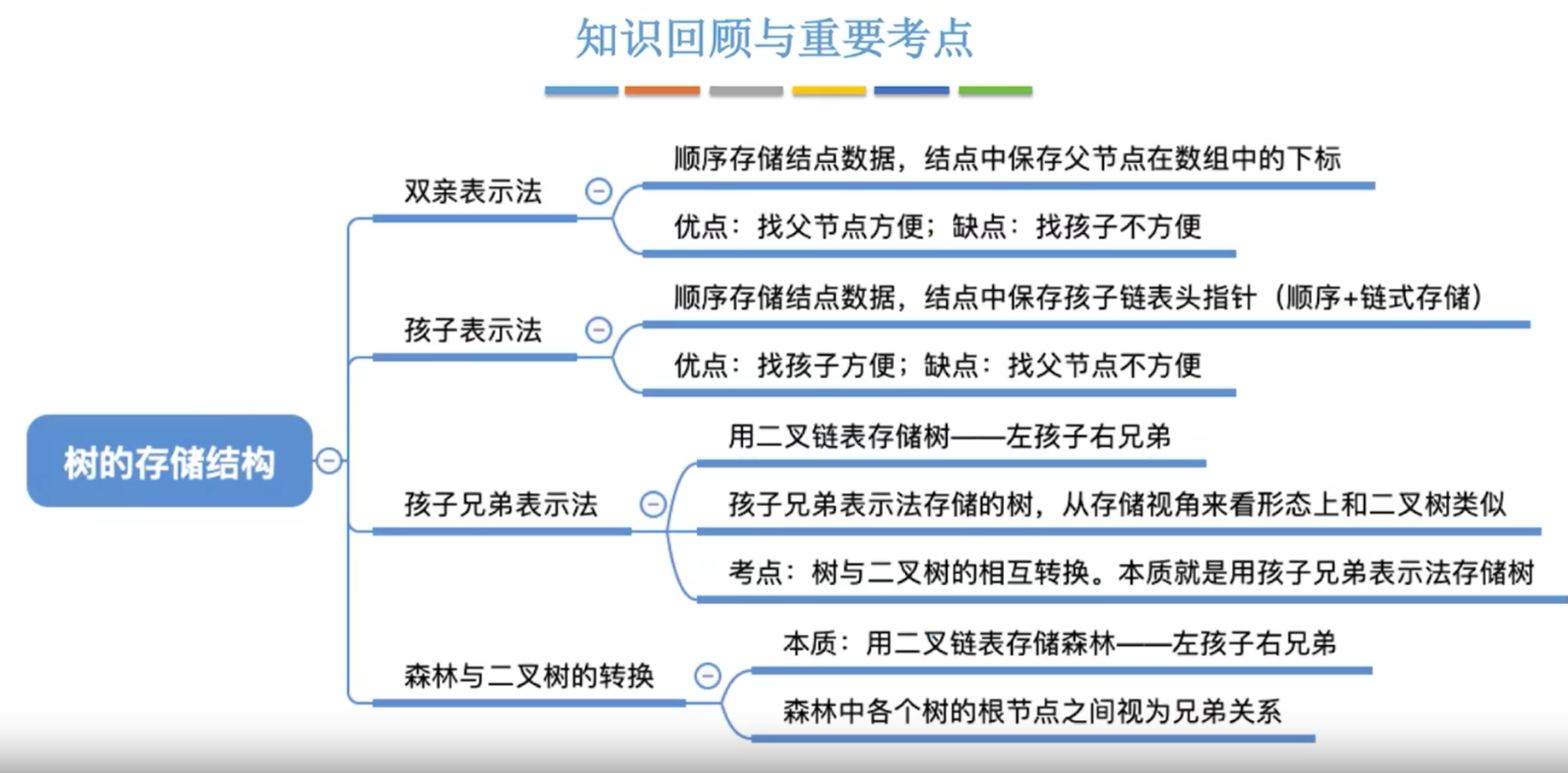
树的存储结构
树和森林的遍历
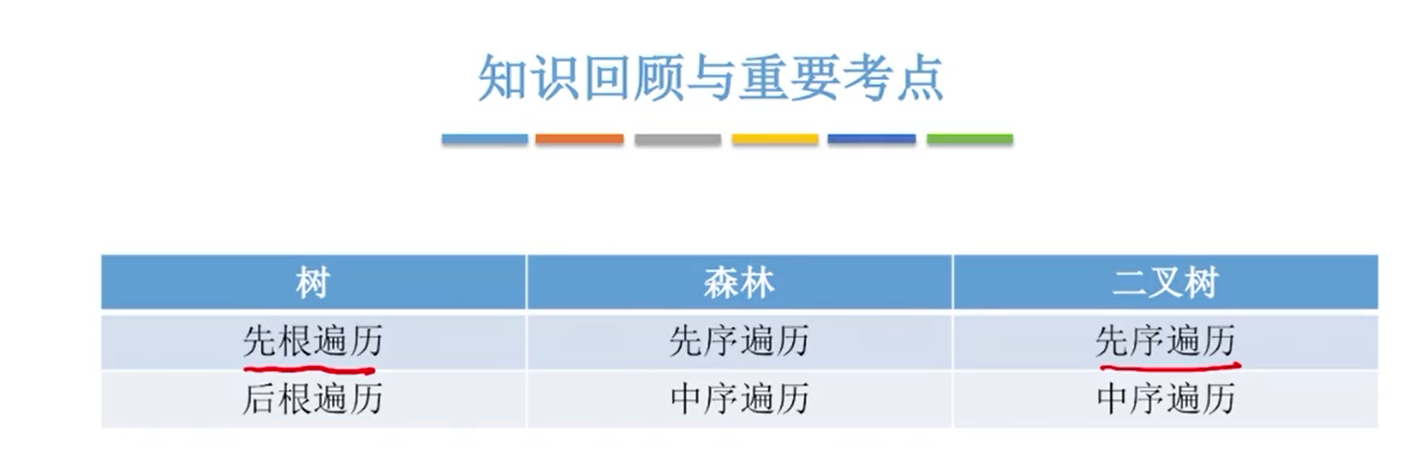
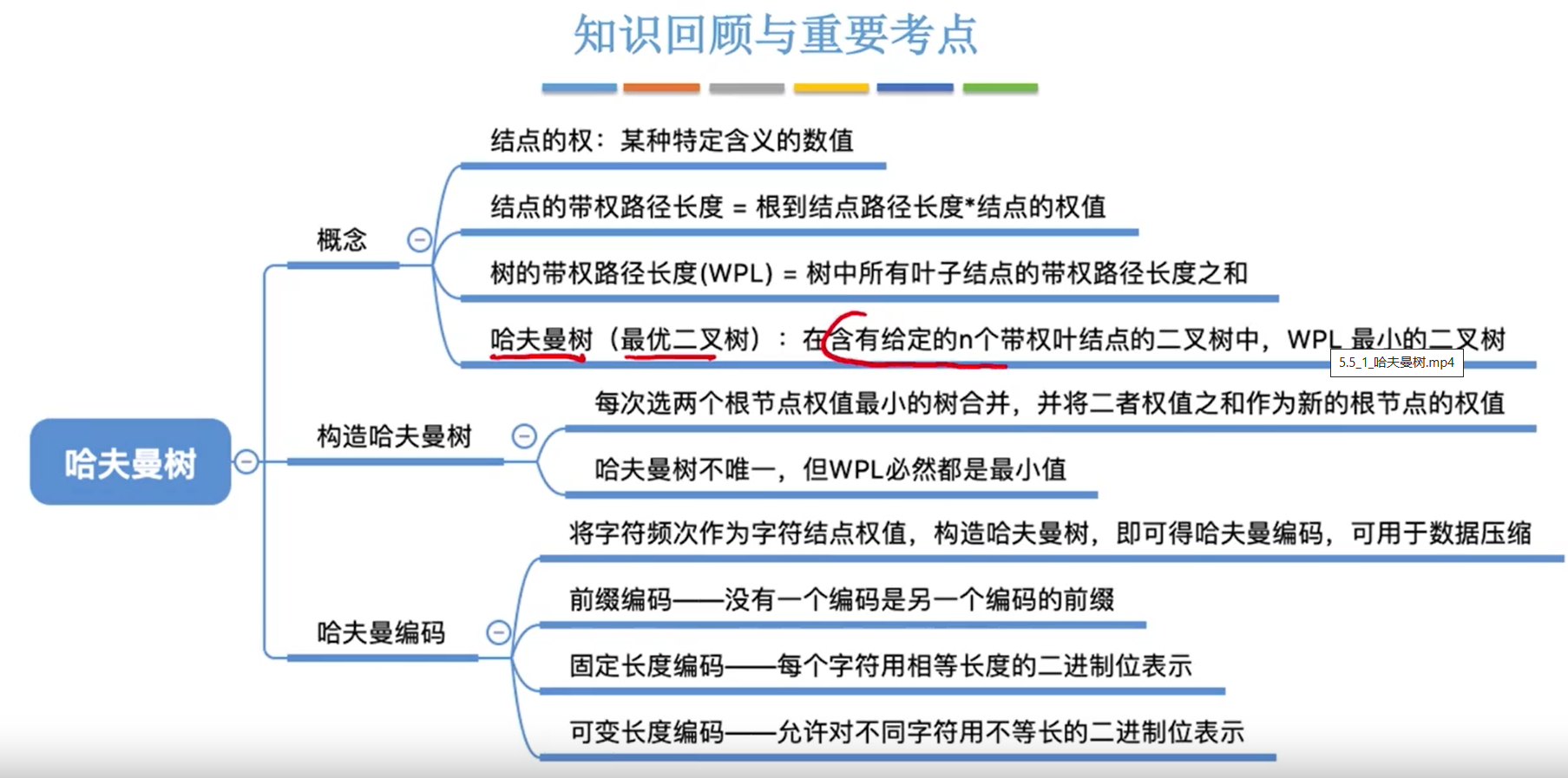
哈夫曼树
并查集

图
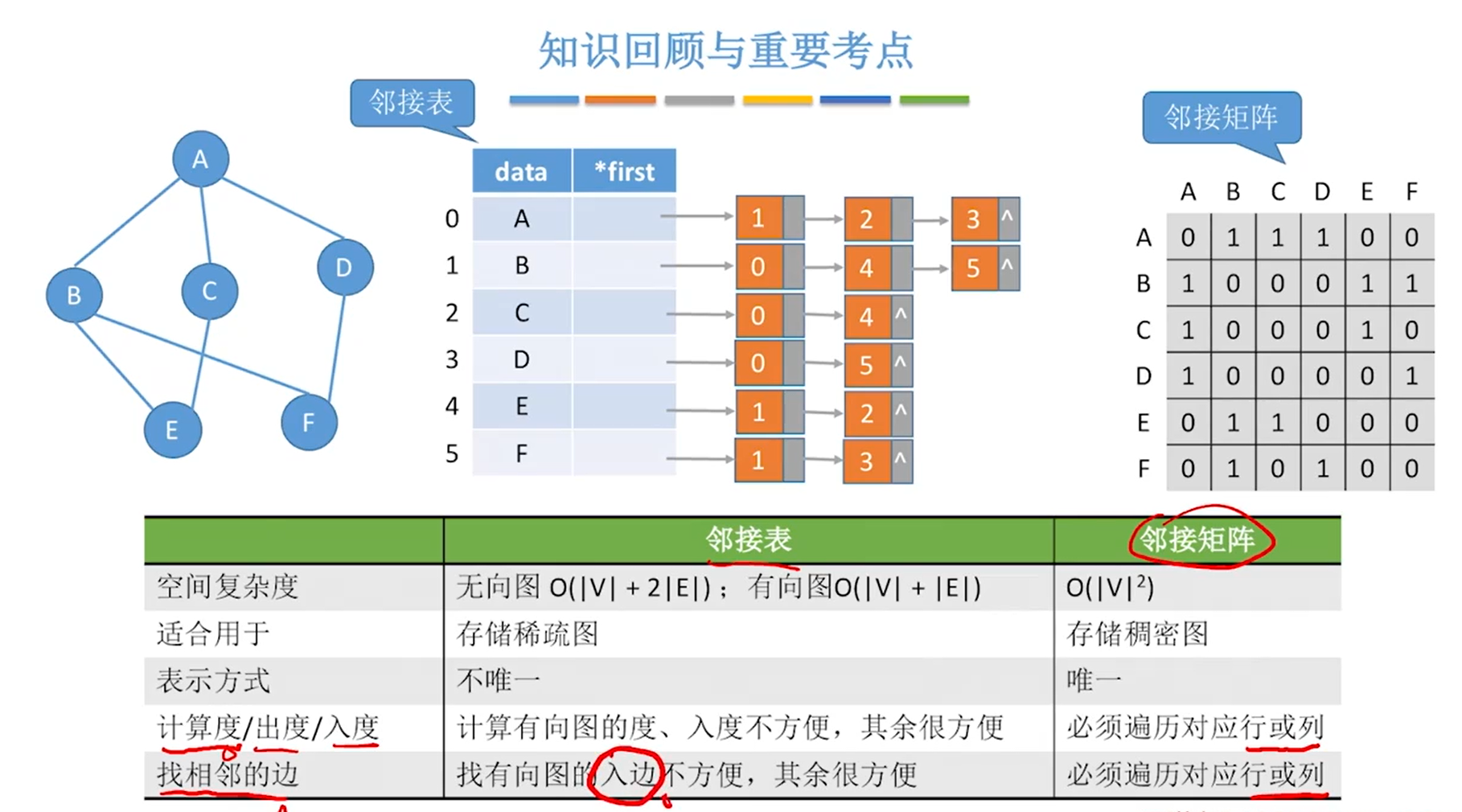
基本概念
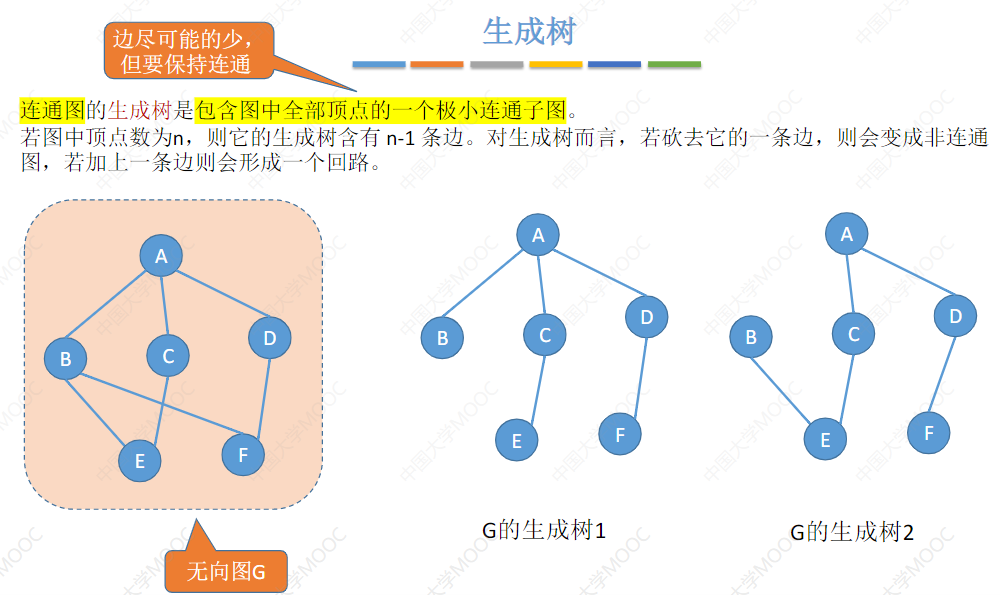
图的存储
邻接矩阵法
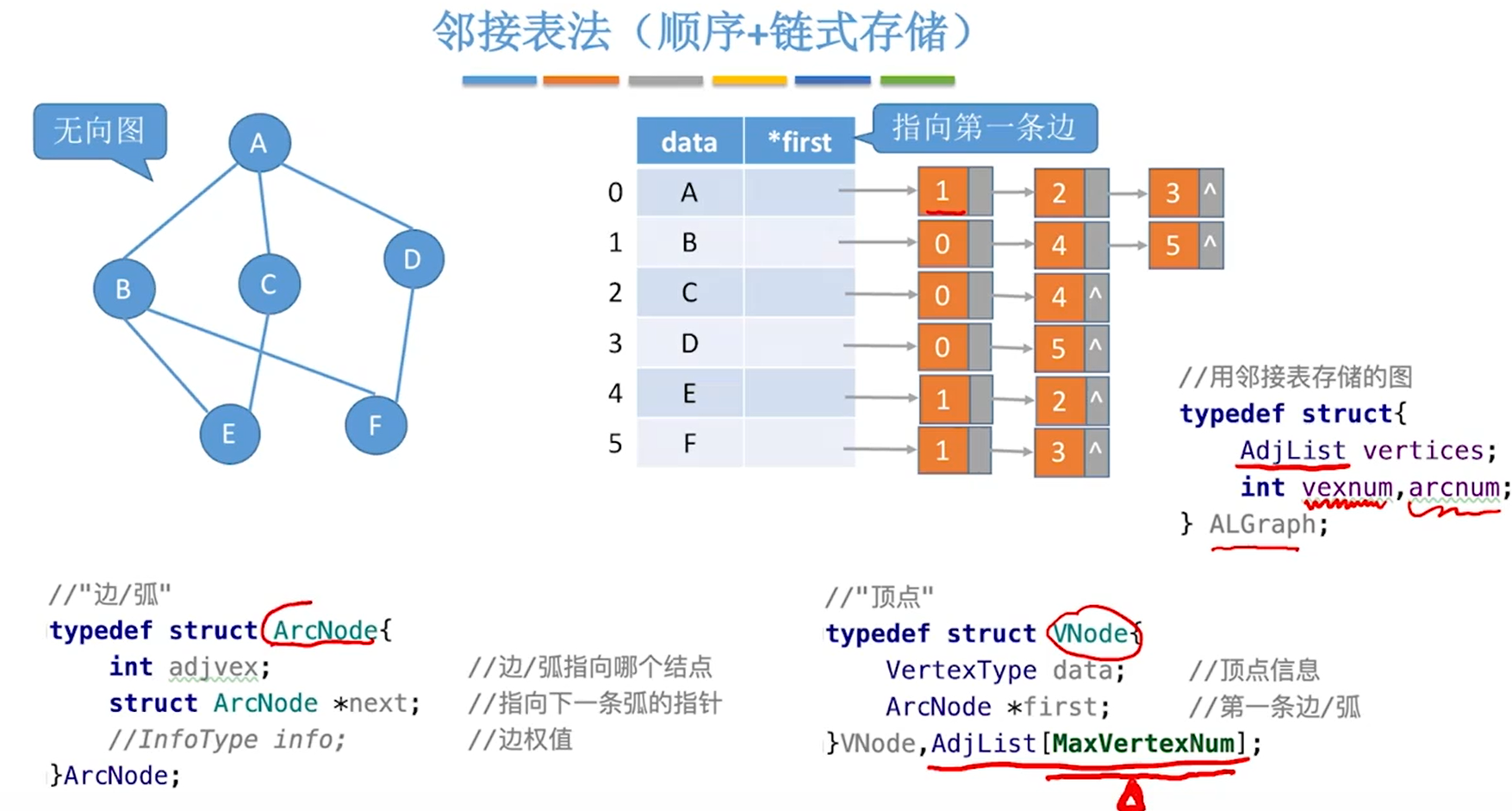
邻接表法
十字链表法
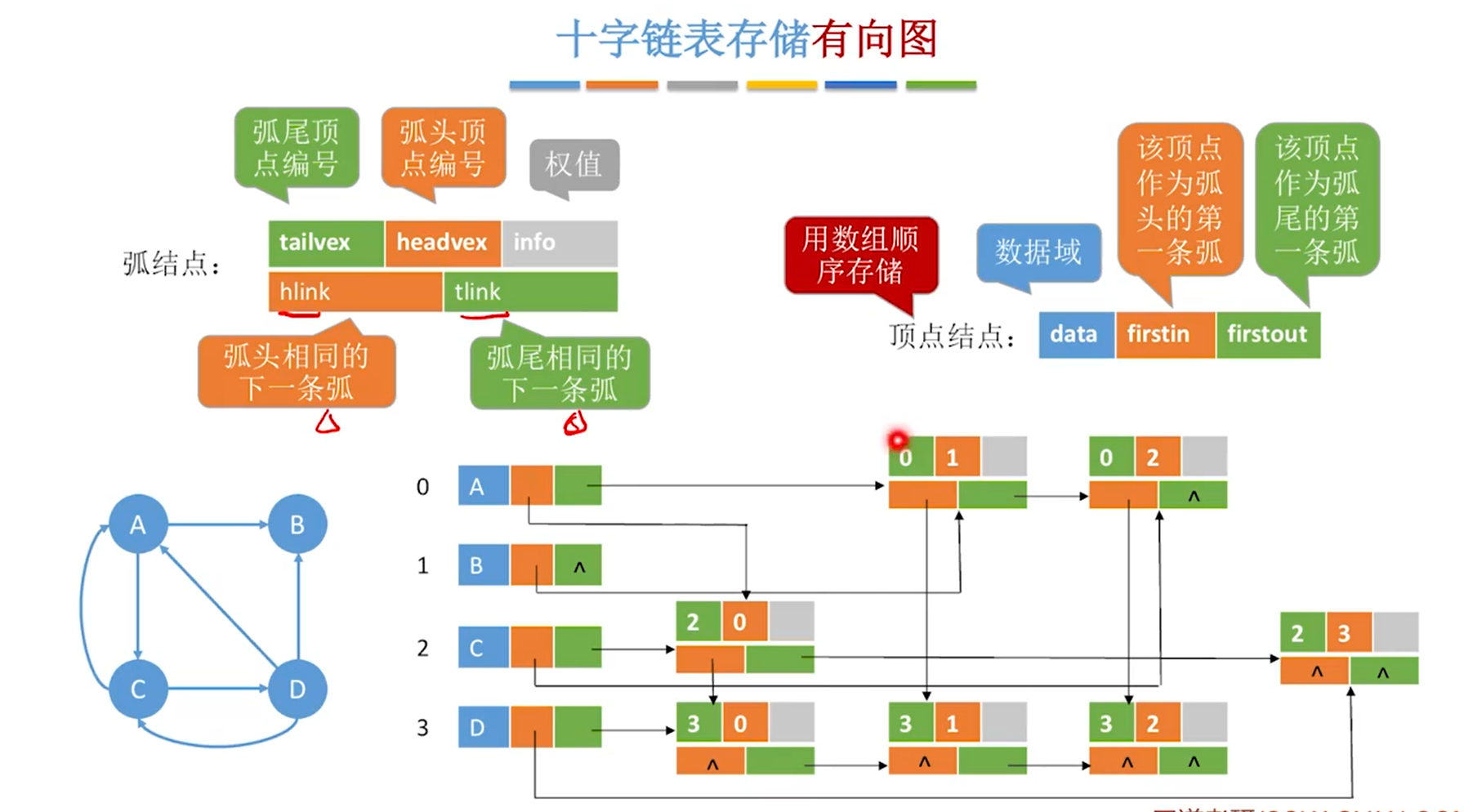
即:顶点结点中绿色色块代表由某条弧指向另一个顶点
橙色色块代表被某个顶点指向
弧结点中下面的色块,绿色代表都是同一个弧尾也即是同一个顶点指向其他顶点,橙色部分代表都指向同一个顶点
重点还是看弧结点中上面的色块很明显的表示了由哪个顶点指向哪个顶点,找某个顶点的出度就是从绿色色块出发,入度就是从橙色色块出发
只能存储有向图
空间复杂度O(|V|+|E|)
邻接矩阵存储无向图,会出现时间复杂度高O(|V|^2)
邻接表存储会出现每条边都有两份冗余信息,删除顶点、边等操作时间复杂度高
邻接多重表
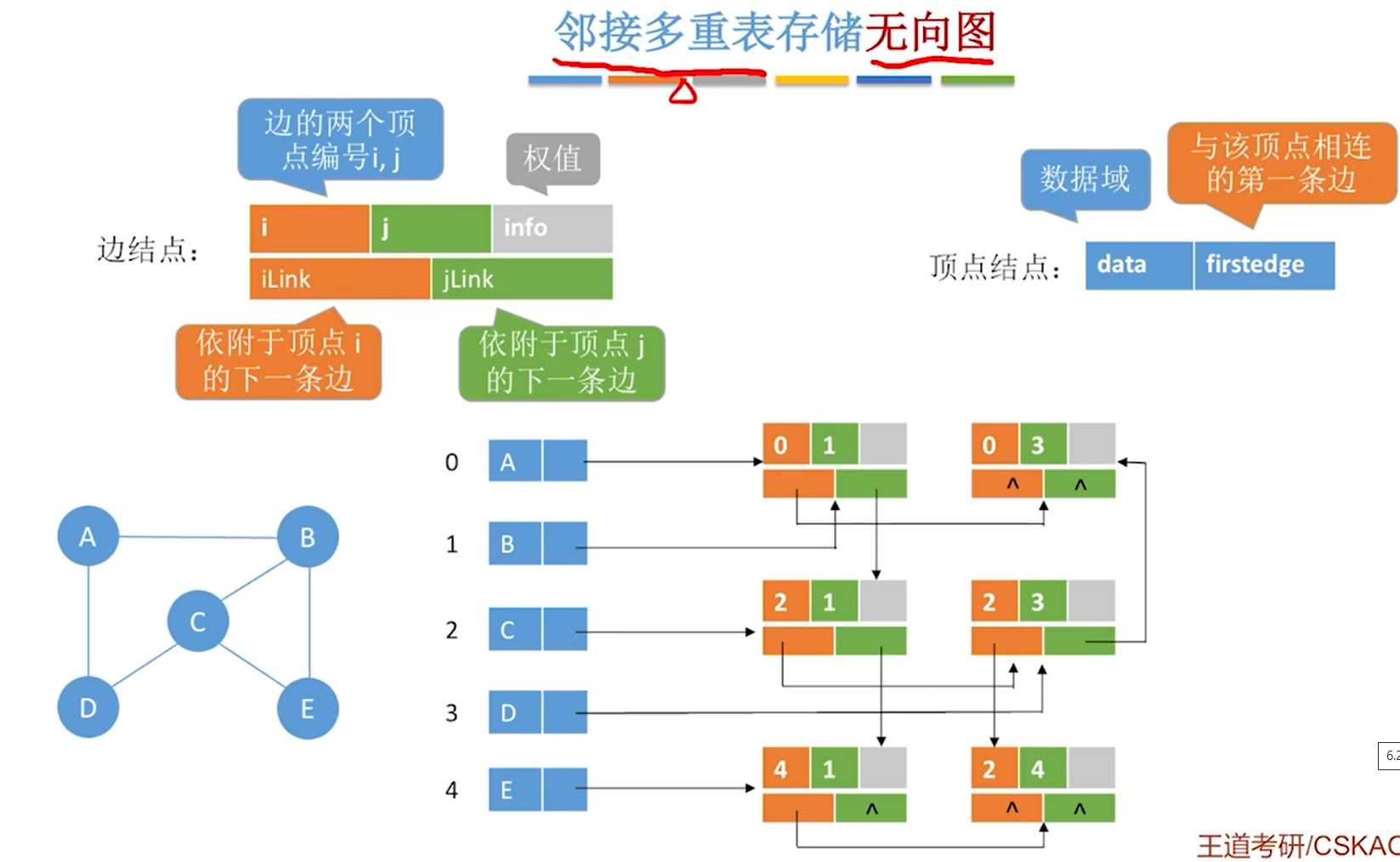
总结

图的基本操作
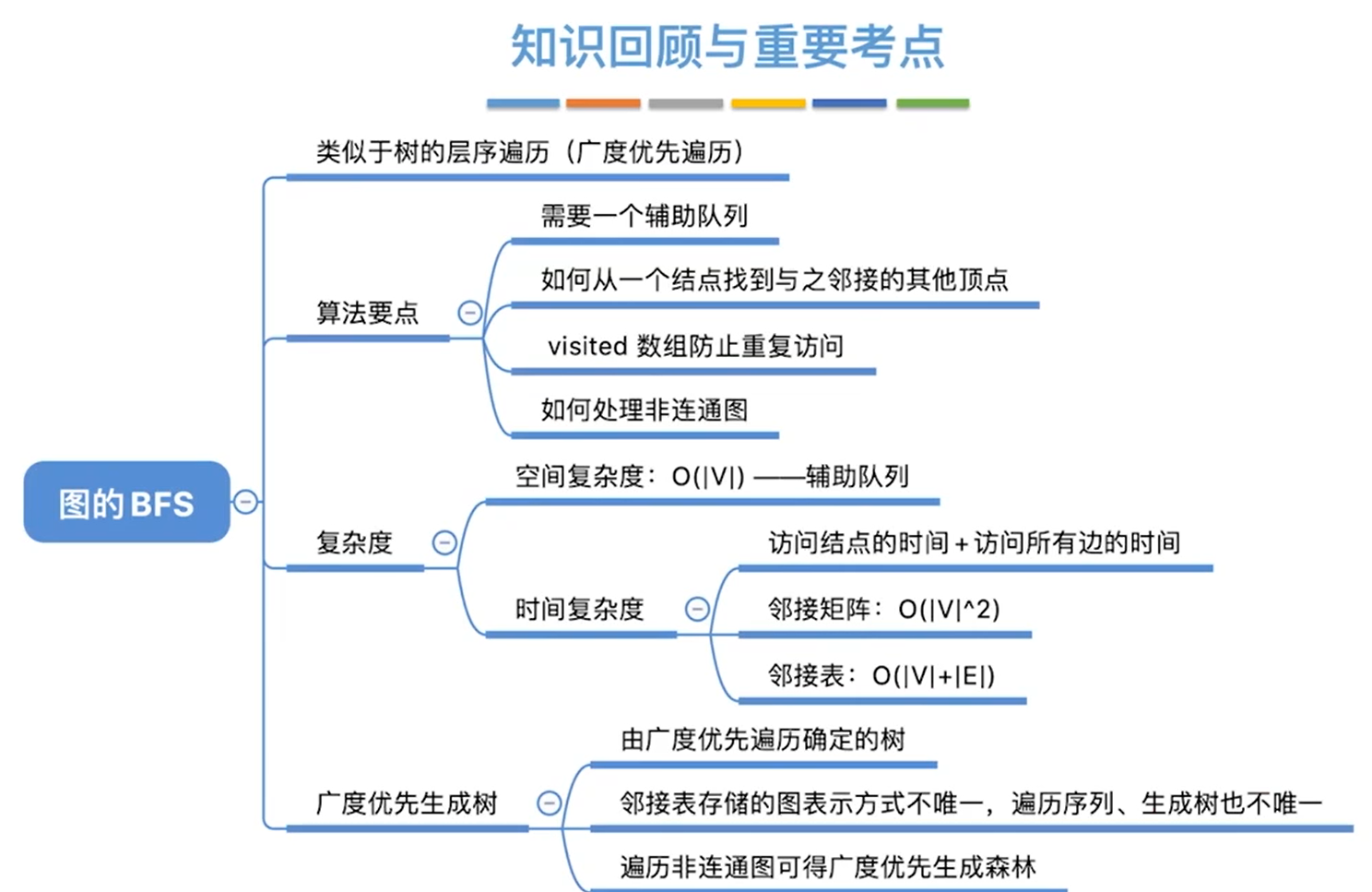
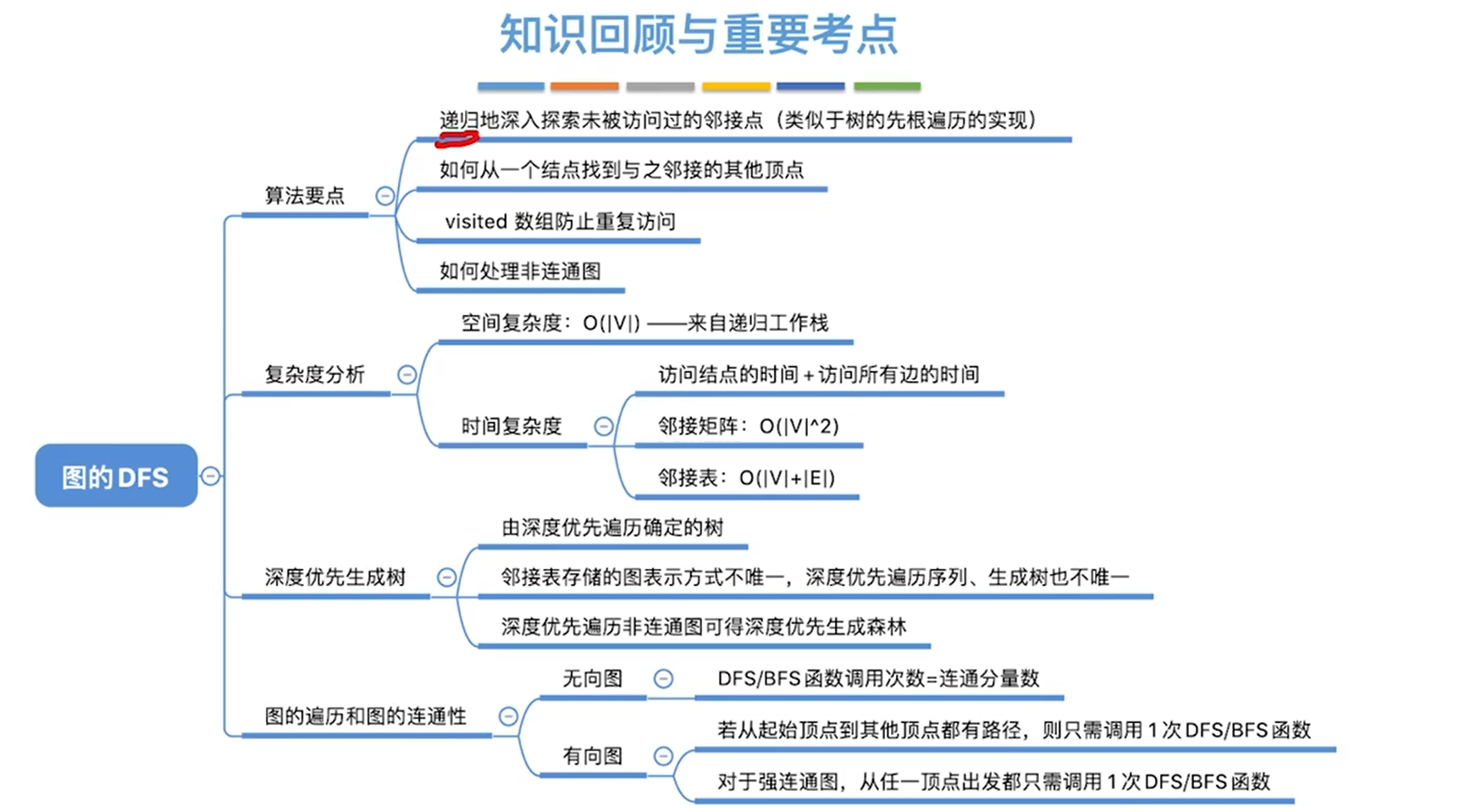
图的遍历
广度优先遍历
深度优先搜索
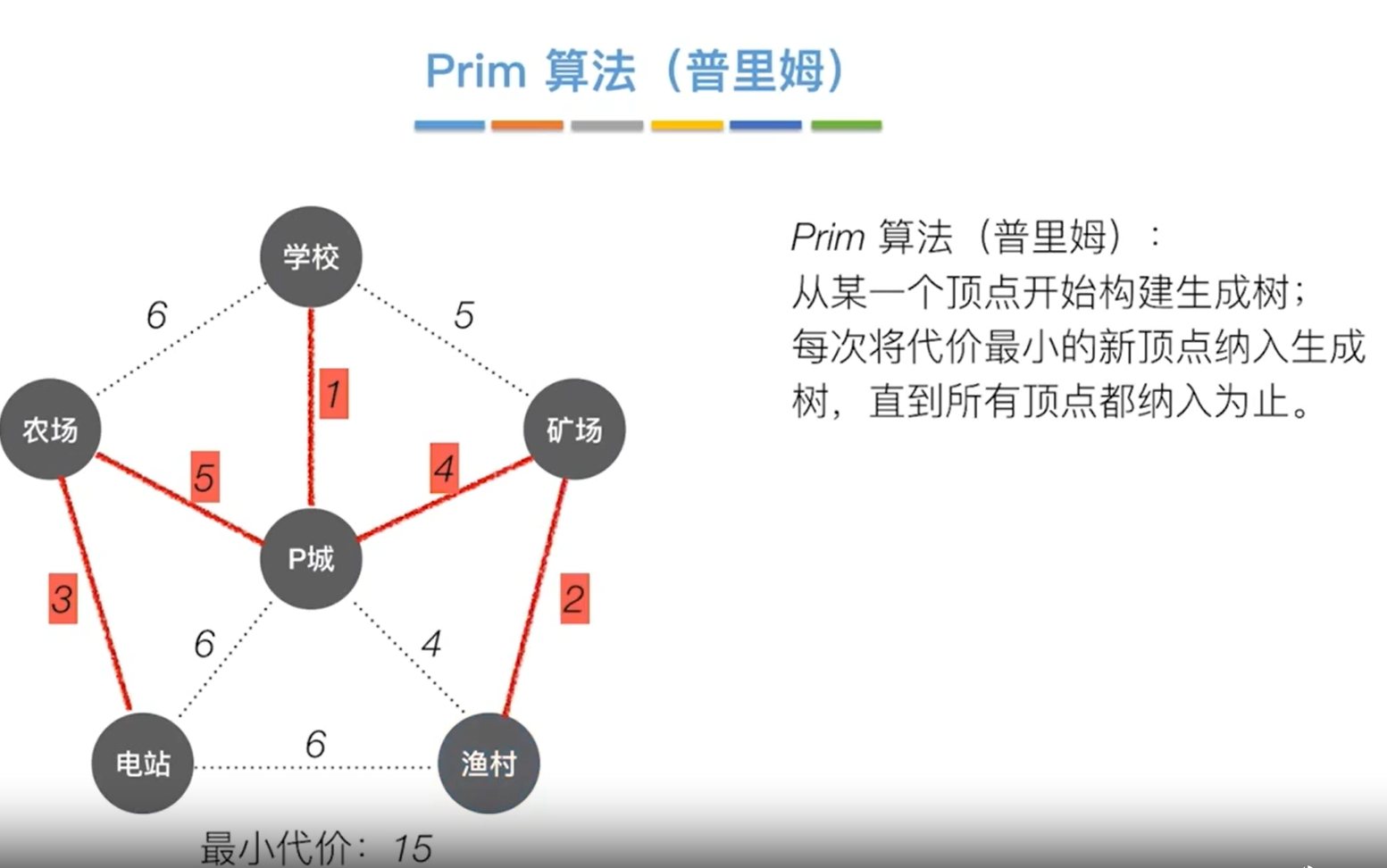
最小生成树
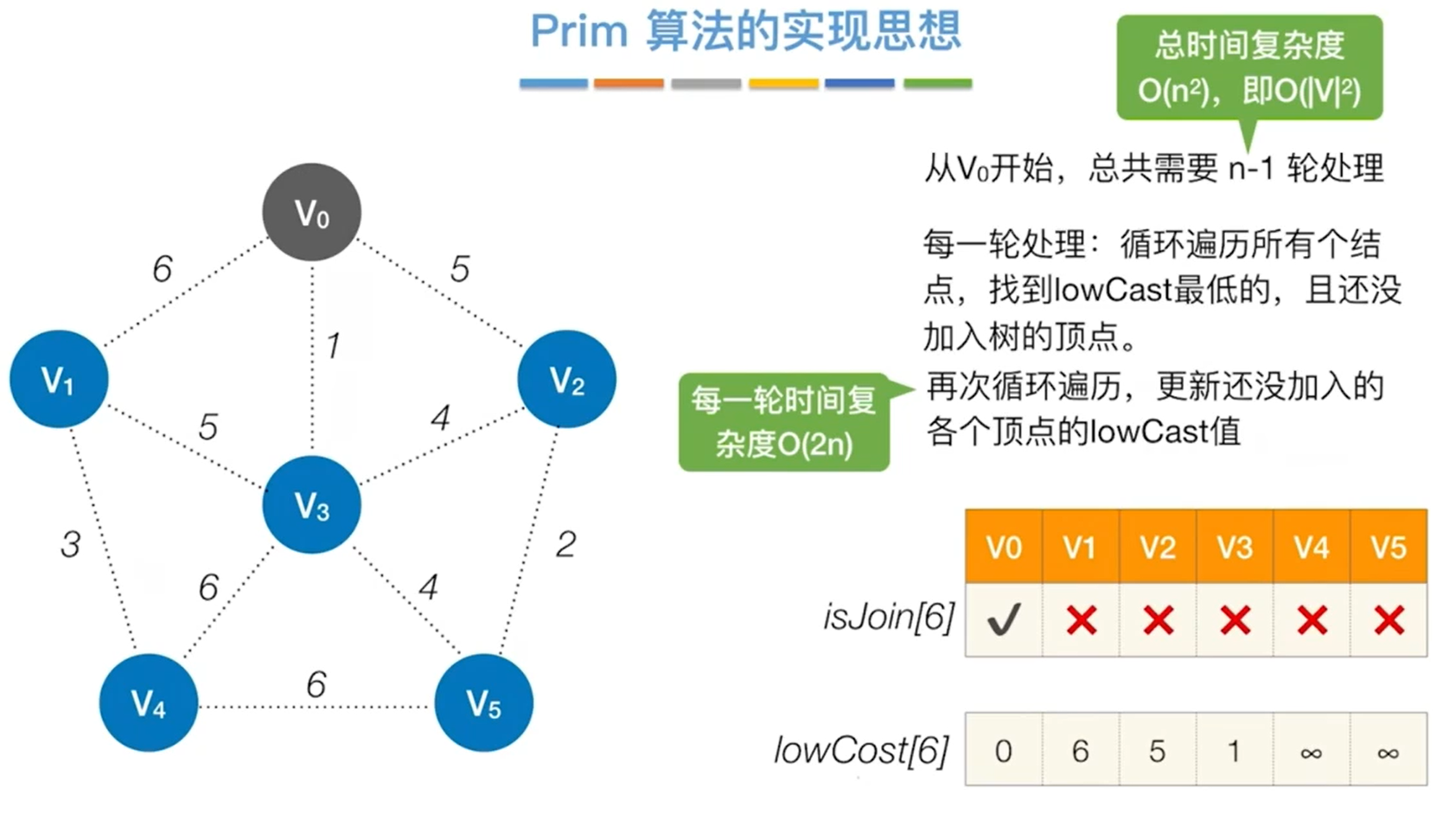
Prim算法
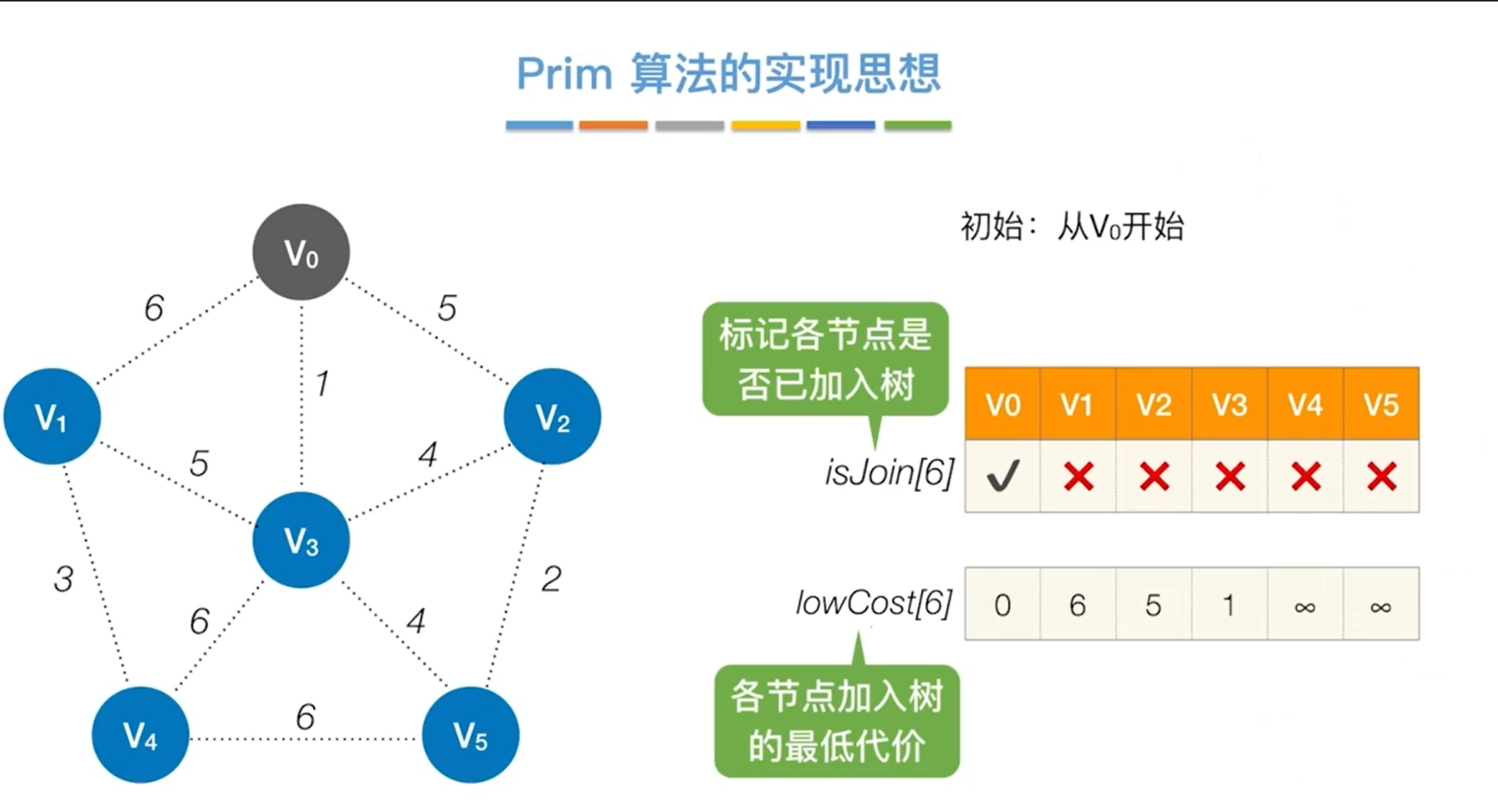
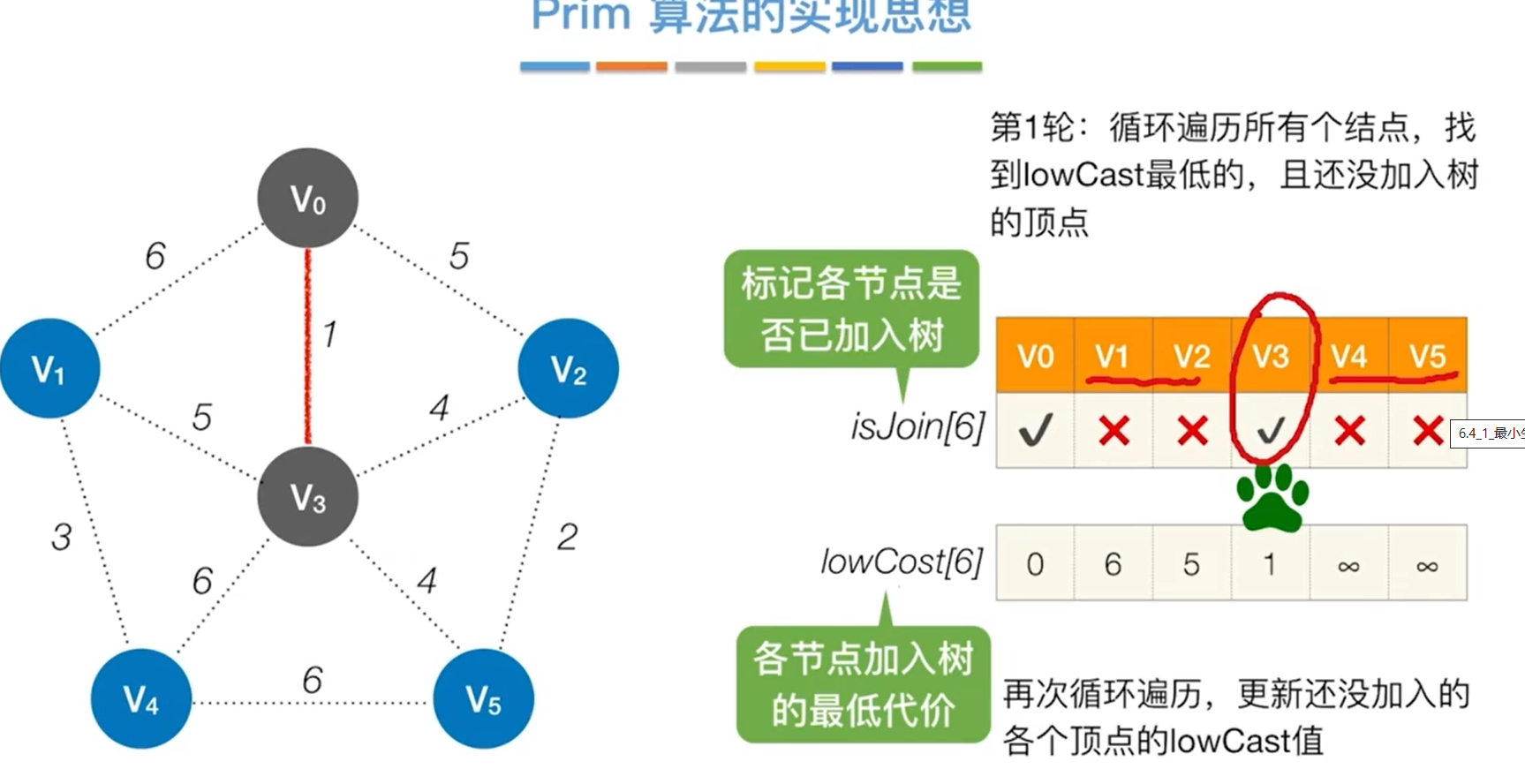
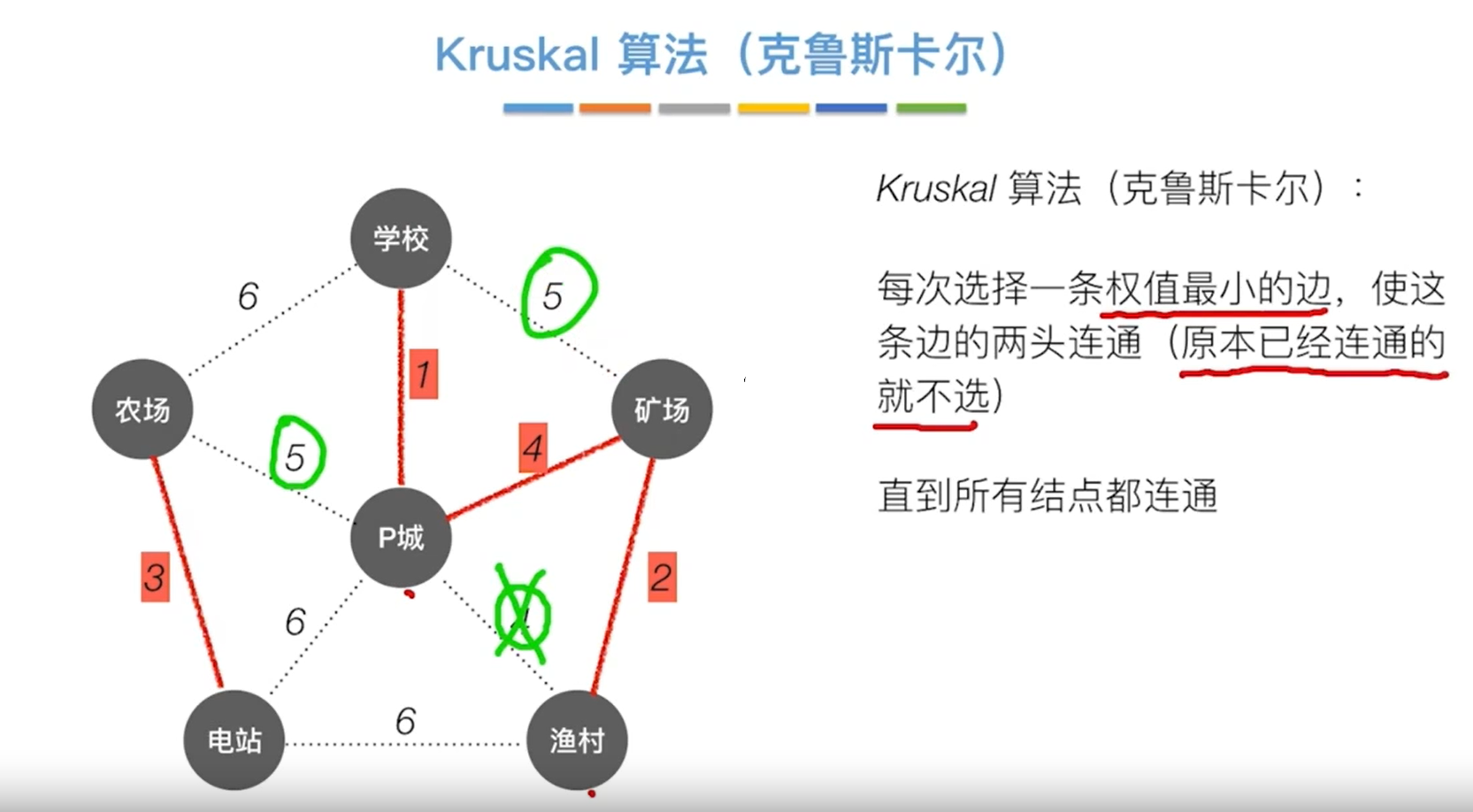
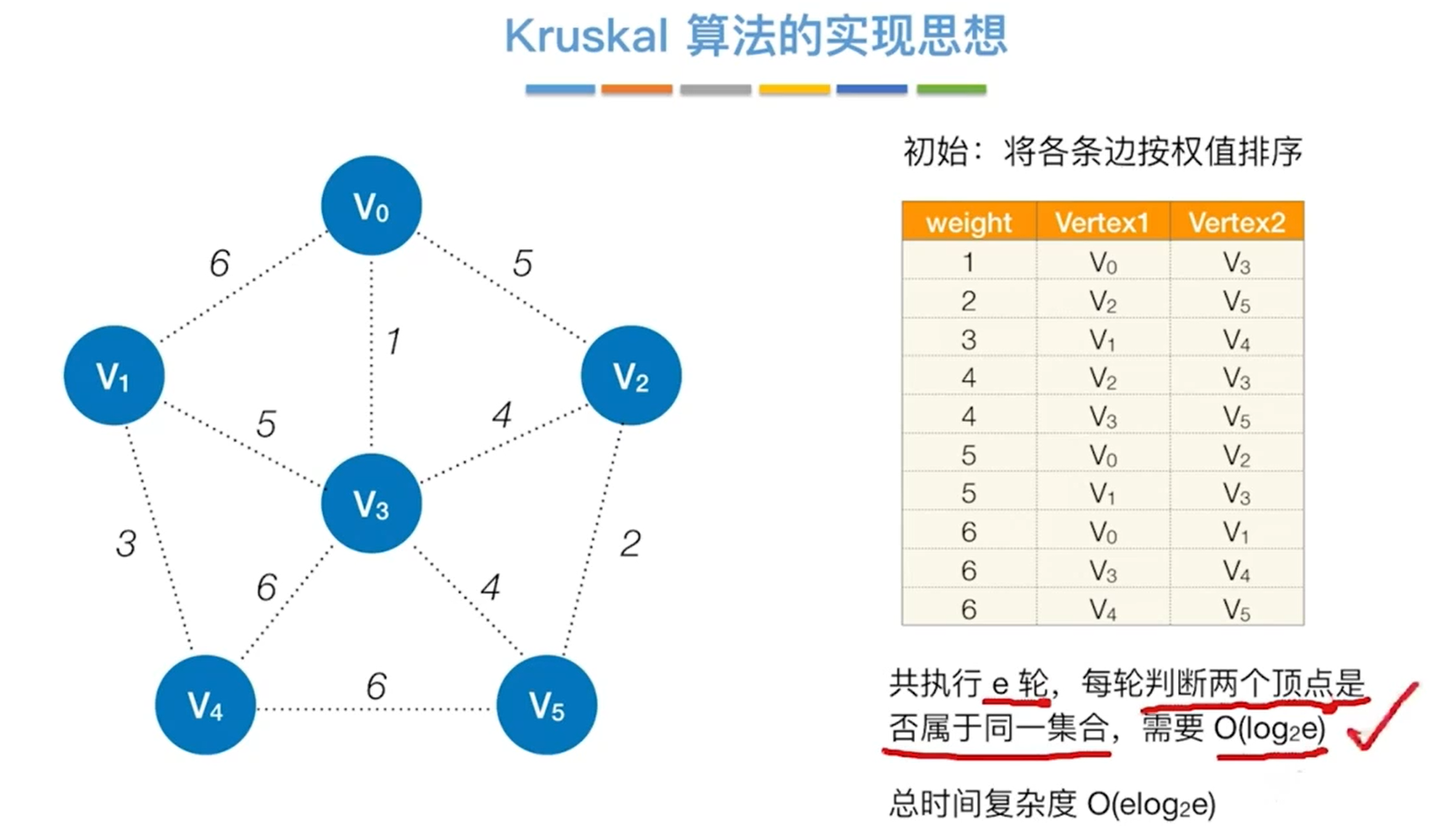
Kruskal算法

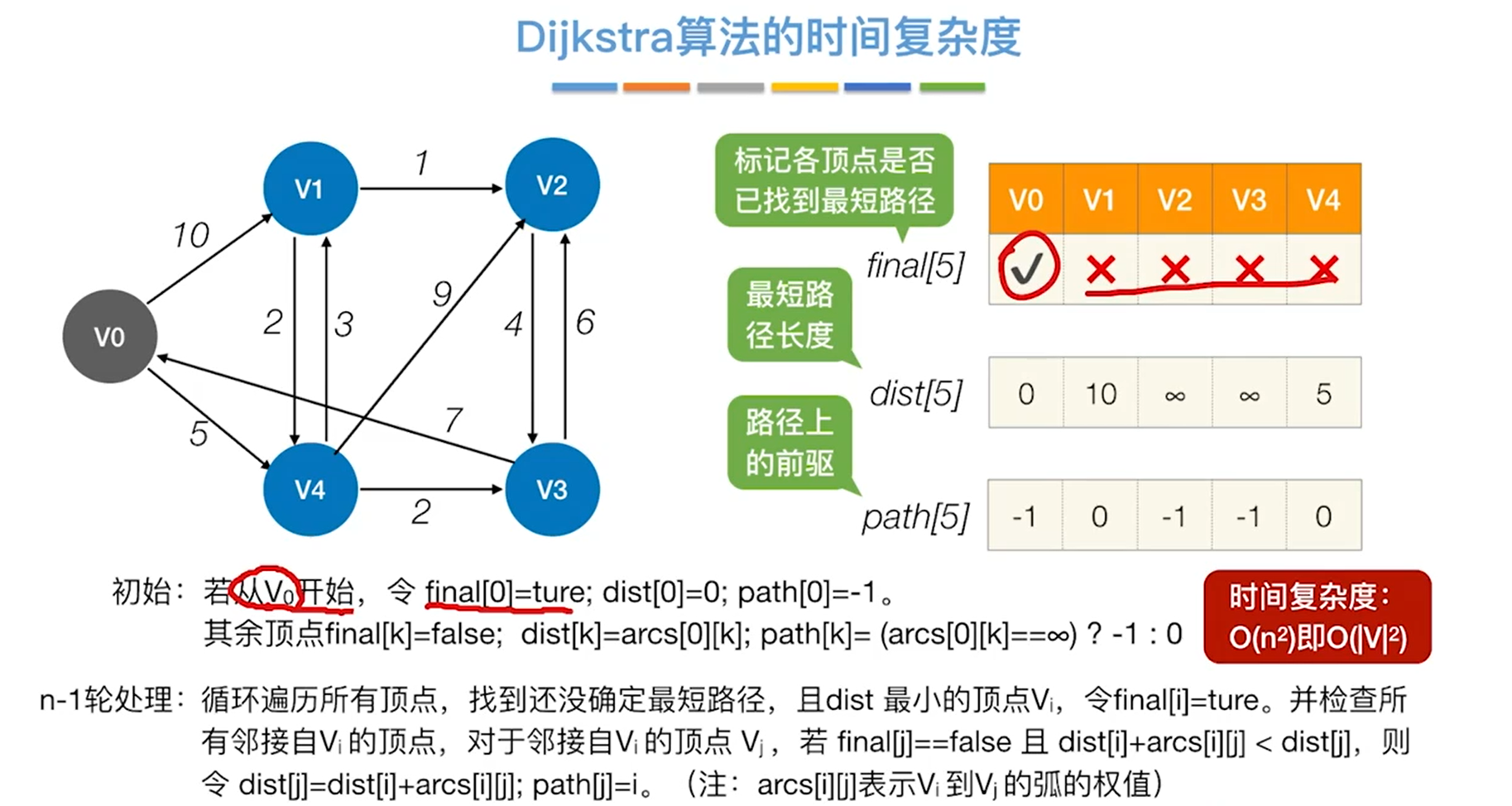
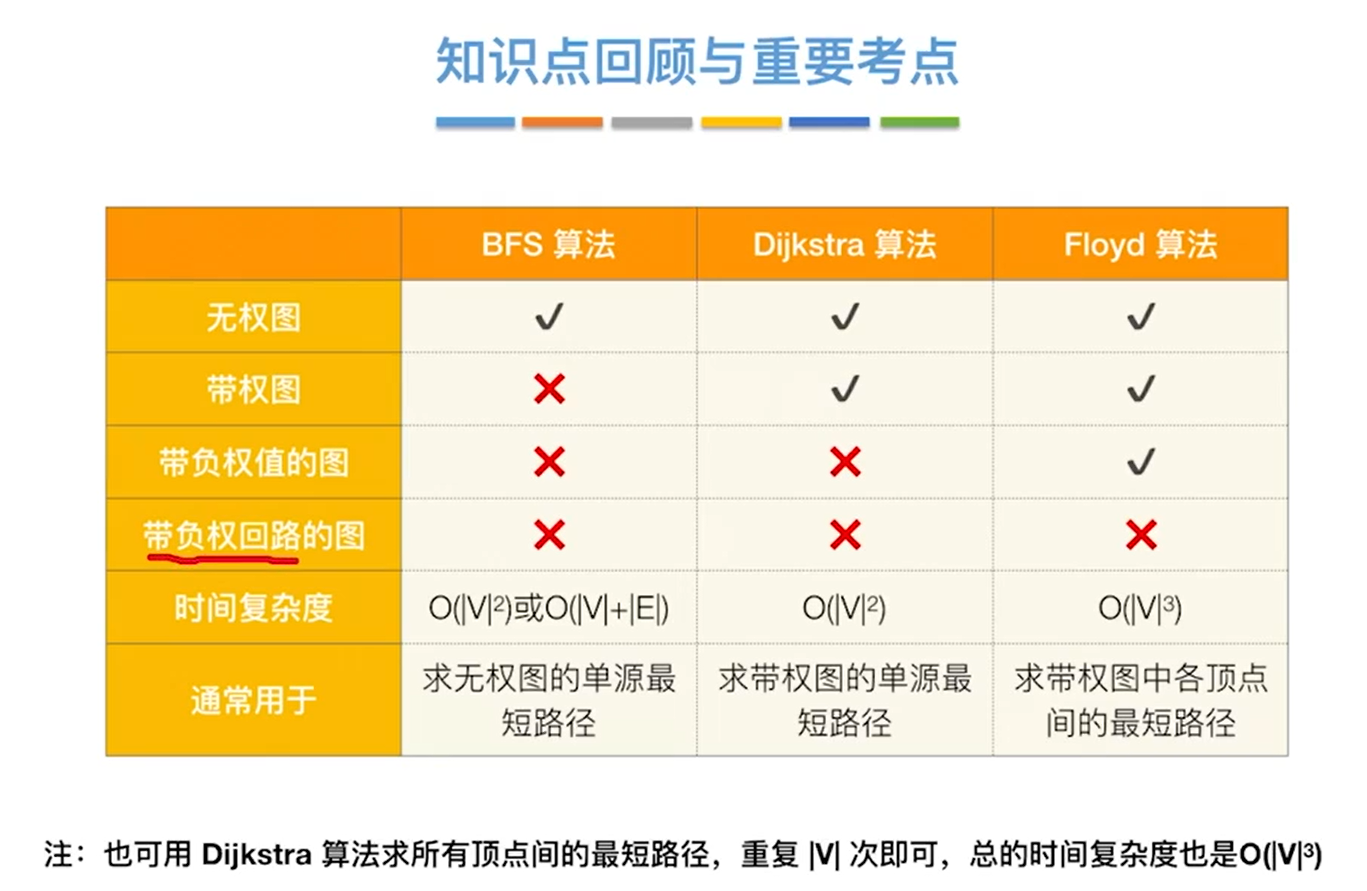
最短路径
单源最短路径
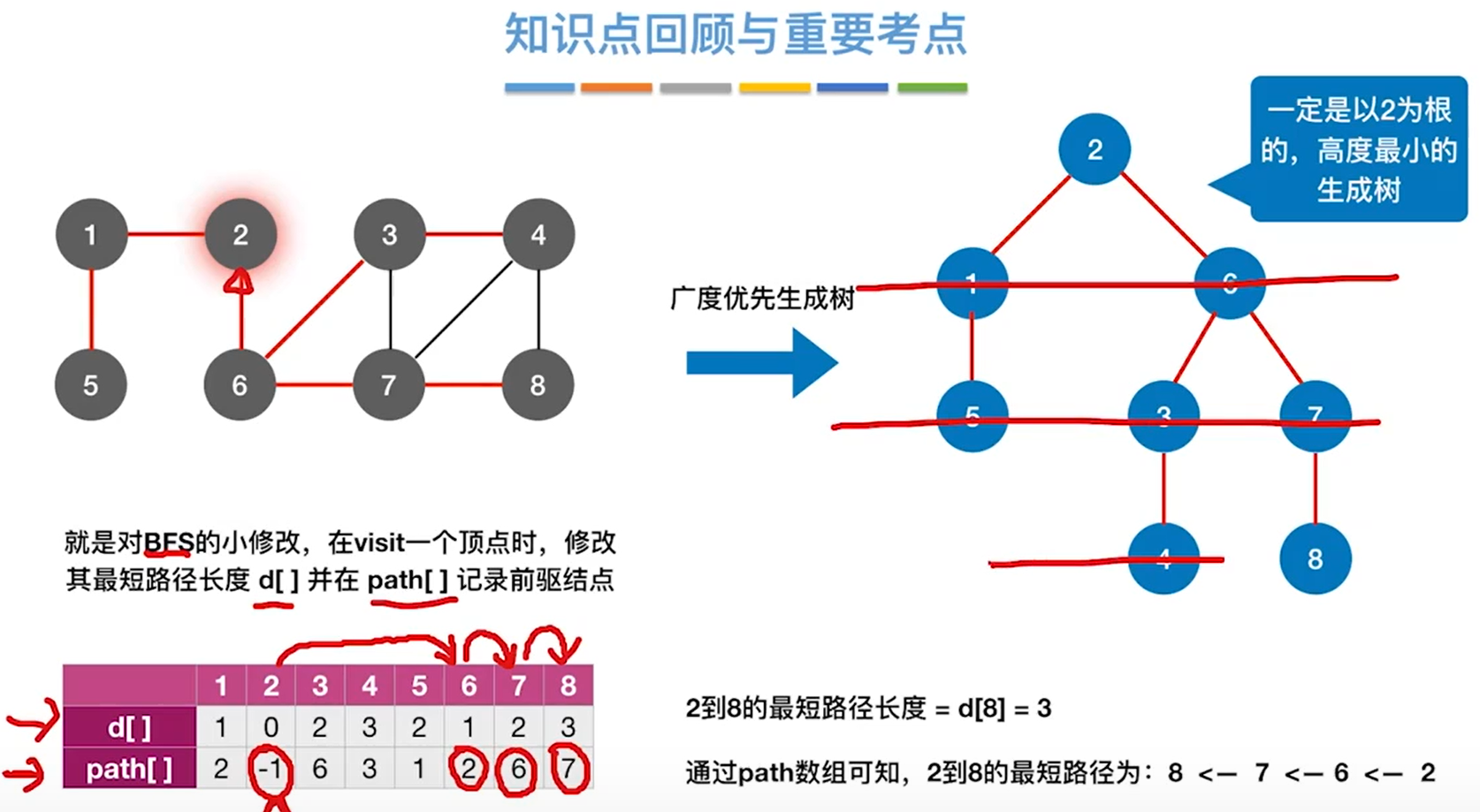
BFS
迪杰斯特拉算法
Floyd


for(int k=0; k<n; k++){//使用Vk做为中转点
for(int i=0;i<n;i++)//遍历矩阵
for(int j=0;j<n;j++){
if(A[i][j]>A[i][k]+A[k][j]){//若以Vk做为中转点路径更小
A[i][j]=A[j][k]+A[k][j];//更新最短路径
path[i][j]=k;//中转点
}
}
}总结
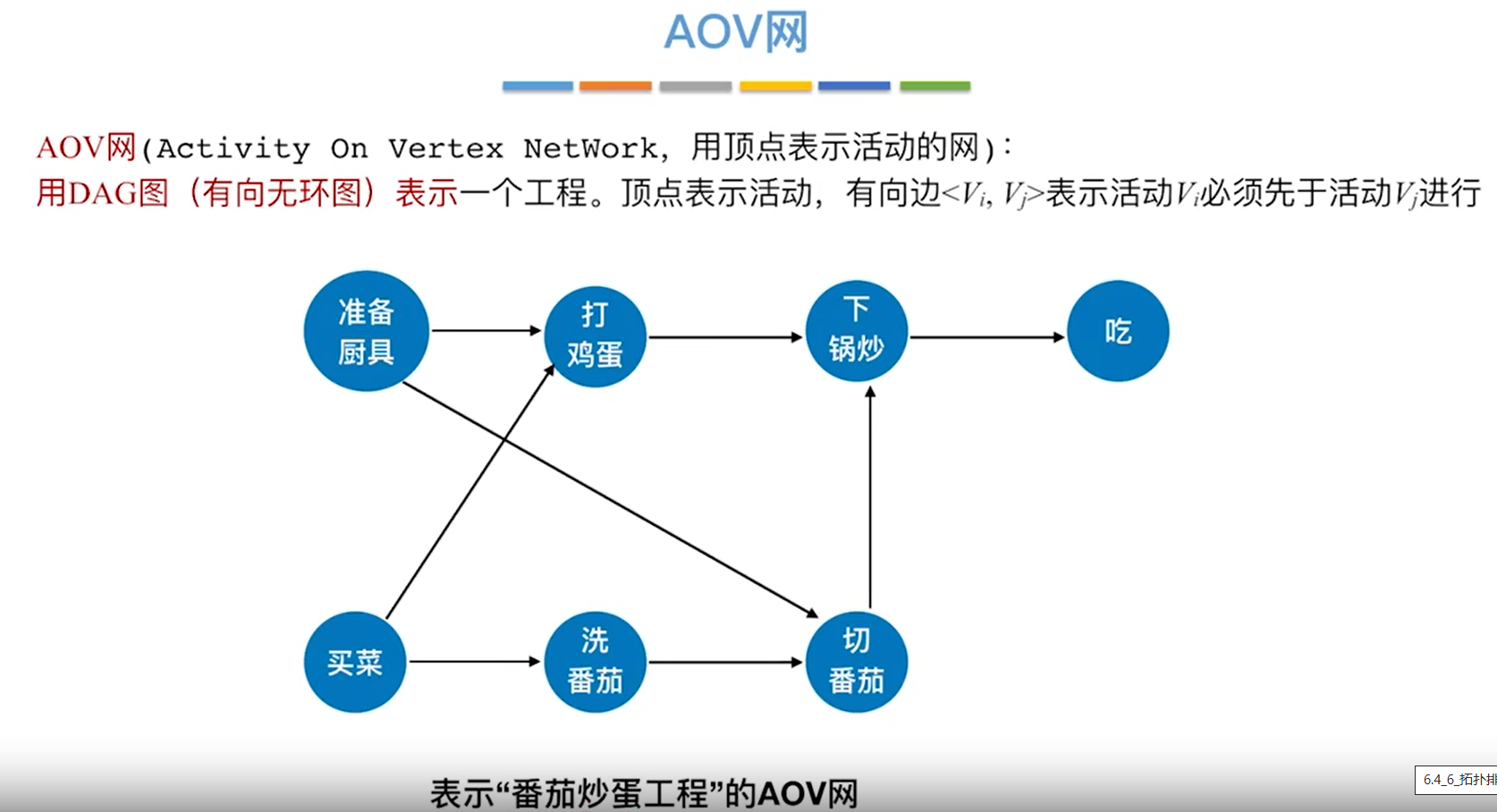
DAG有向无环图
若一个有向图中不存在环,则称为有向无环图。
拓扑
拓扑排序
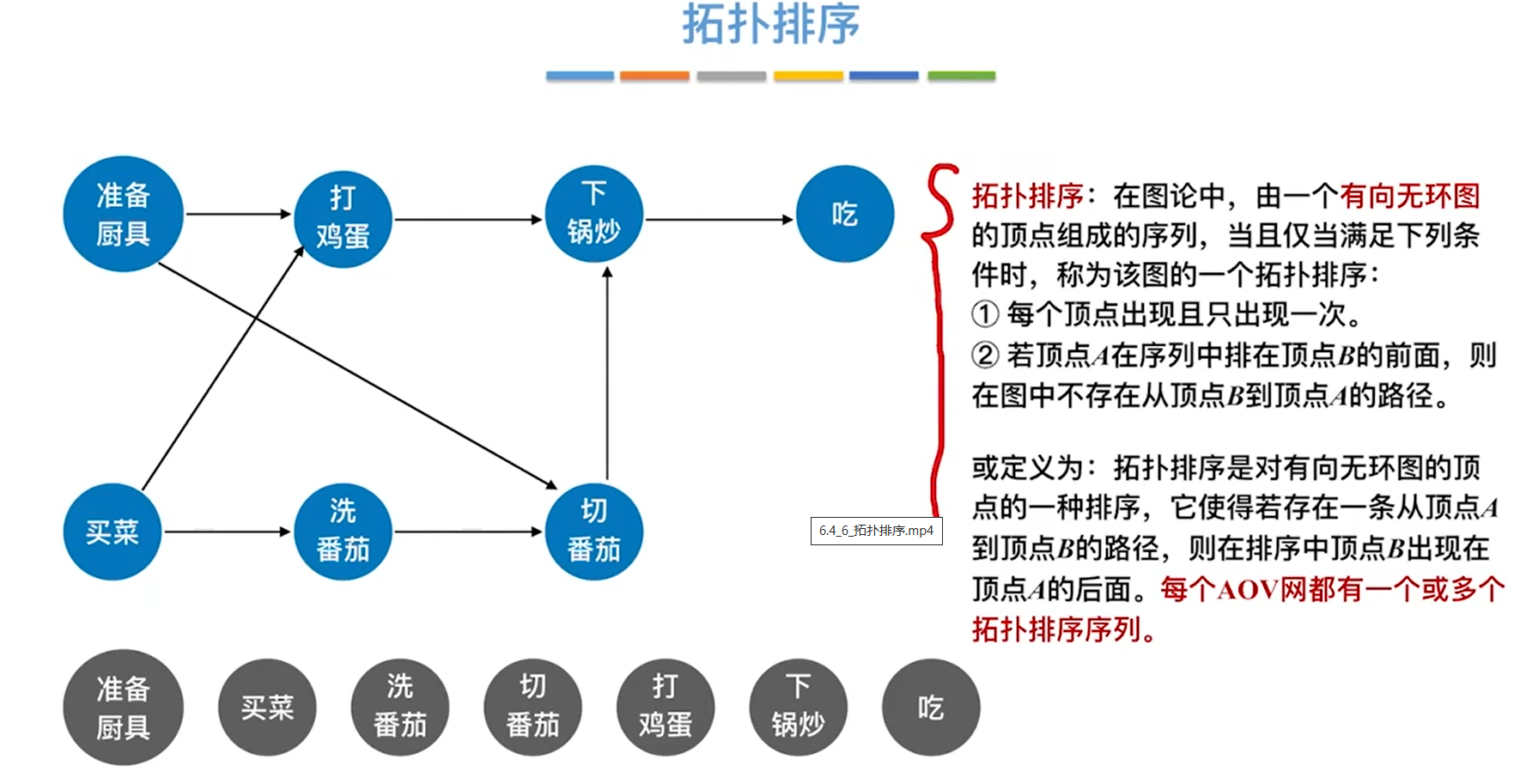

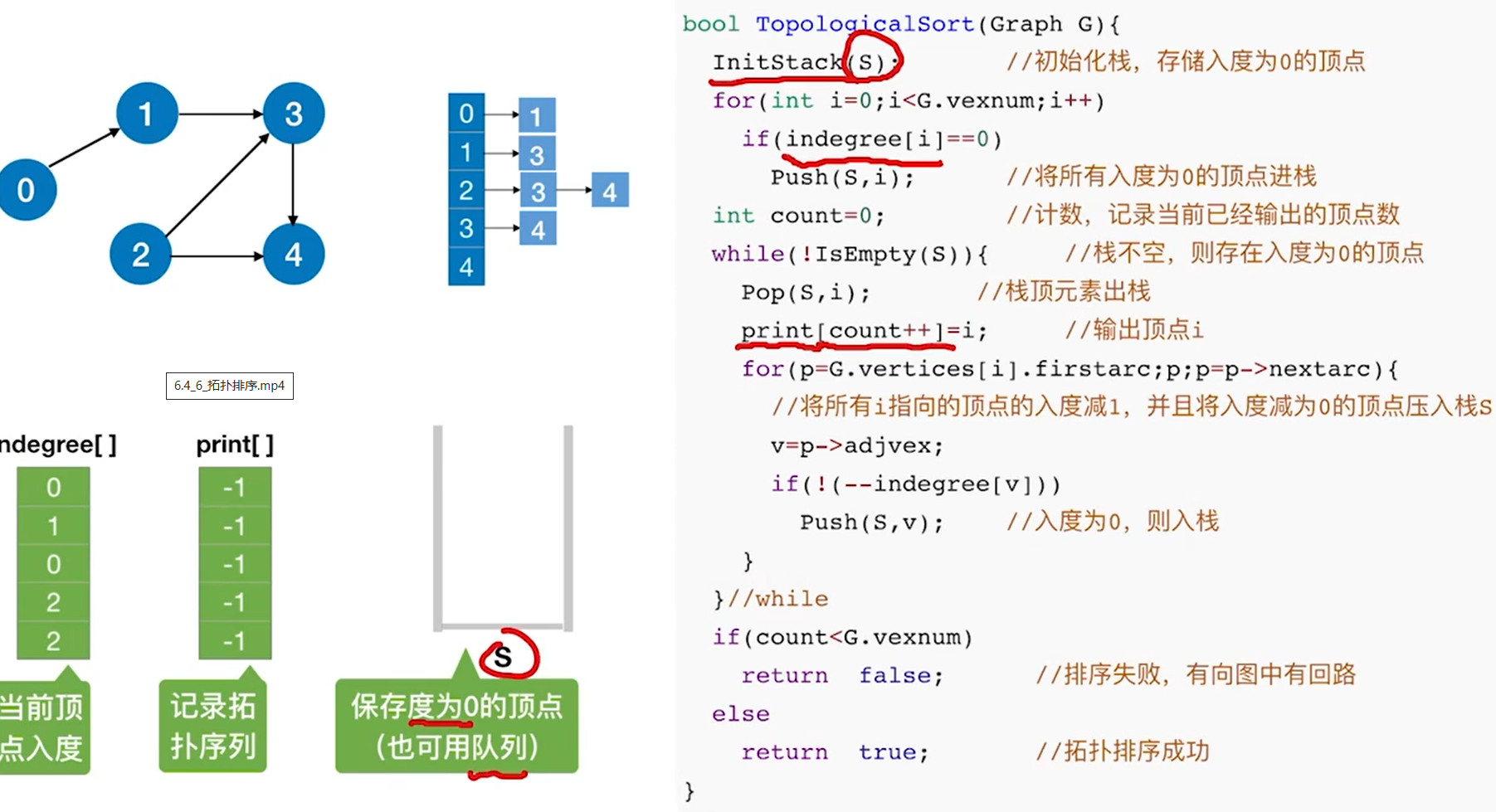
时间复杂度O(|V|+|E|),若是邻接矩阵存储,时间复杂度为O(V2)
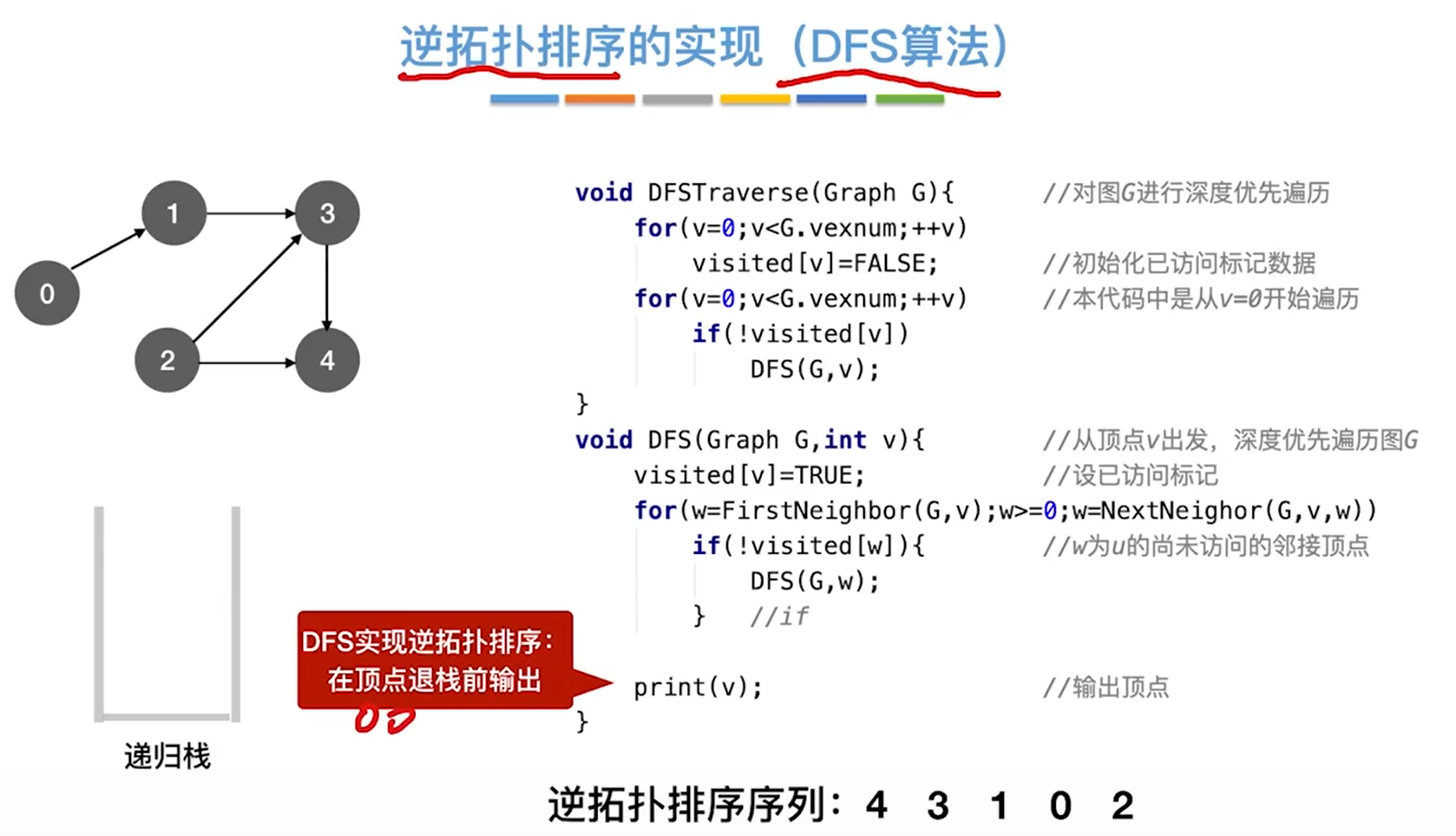
逆拓扑排序
删除出度为0结点
邻接矩阵使用比较好,或逆邻接表

总结

关键路径
AOE网
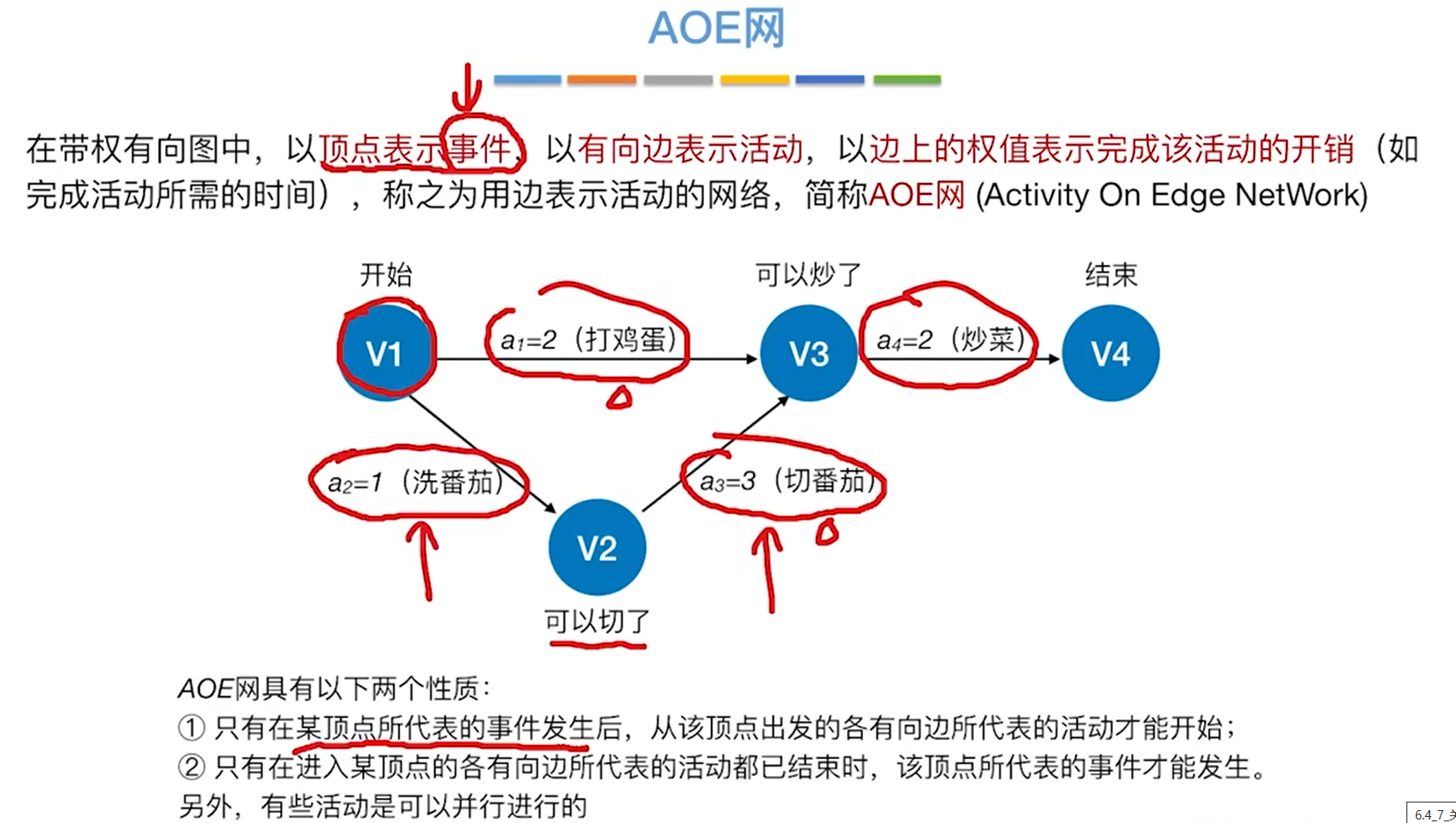

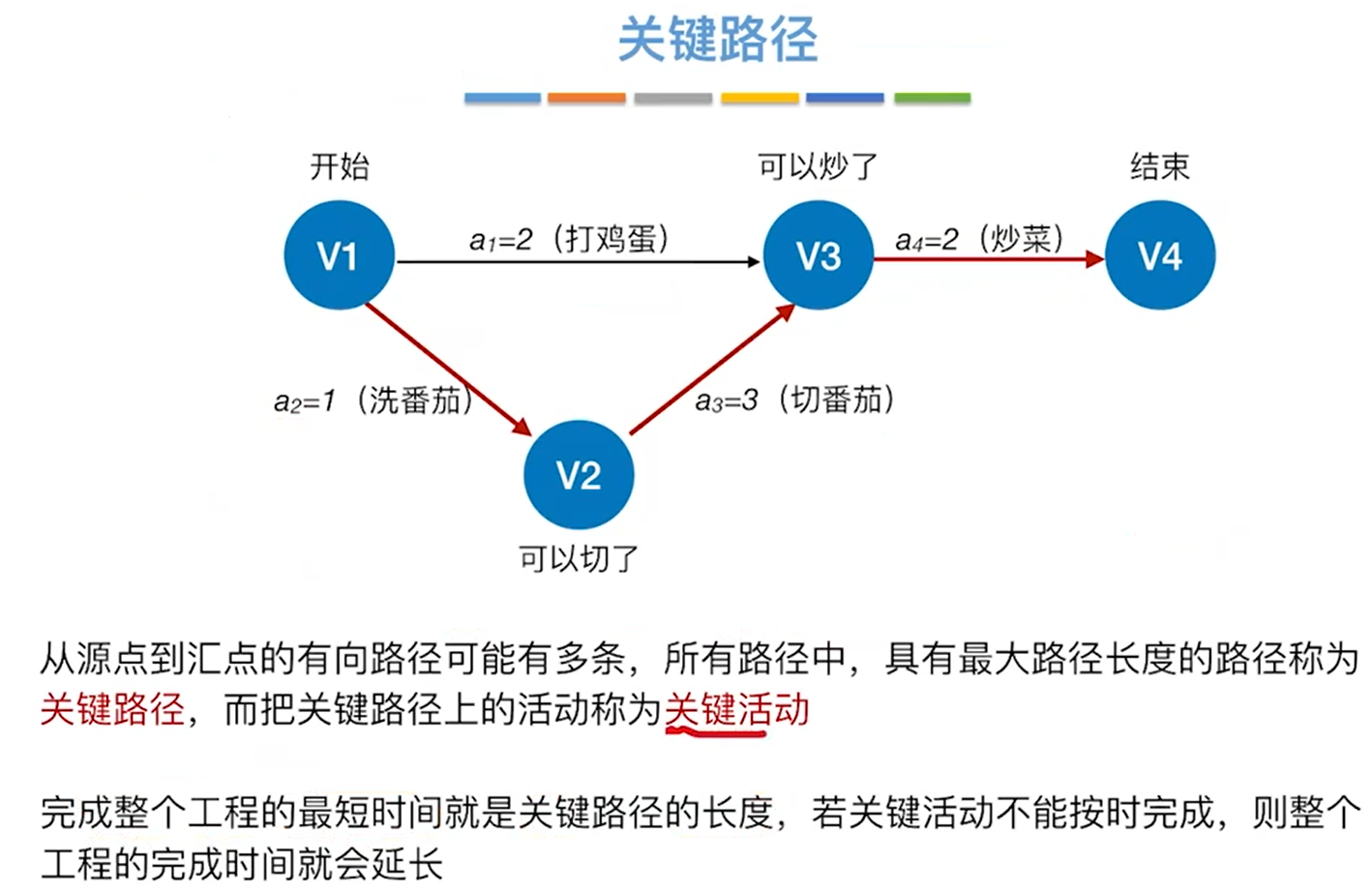

有可能有多条

求解方法

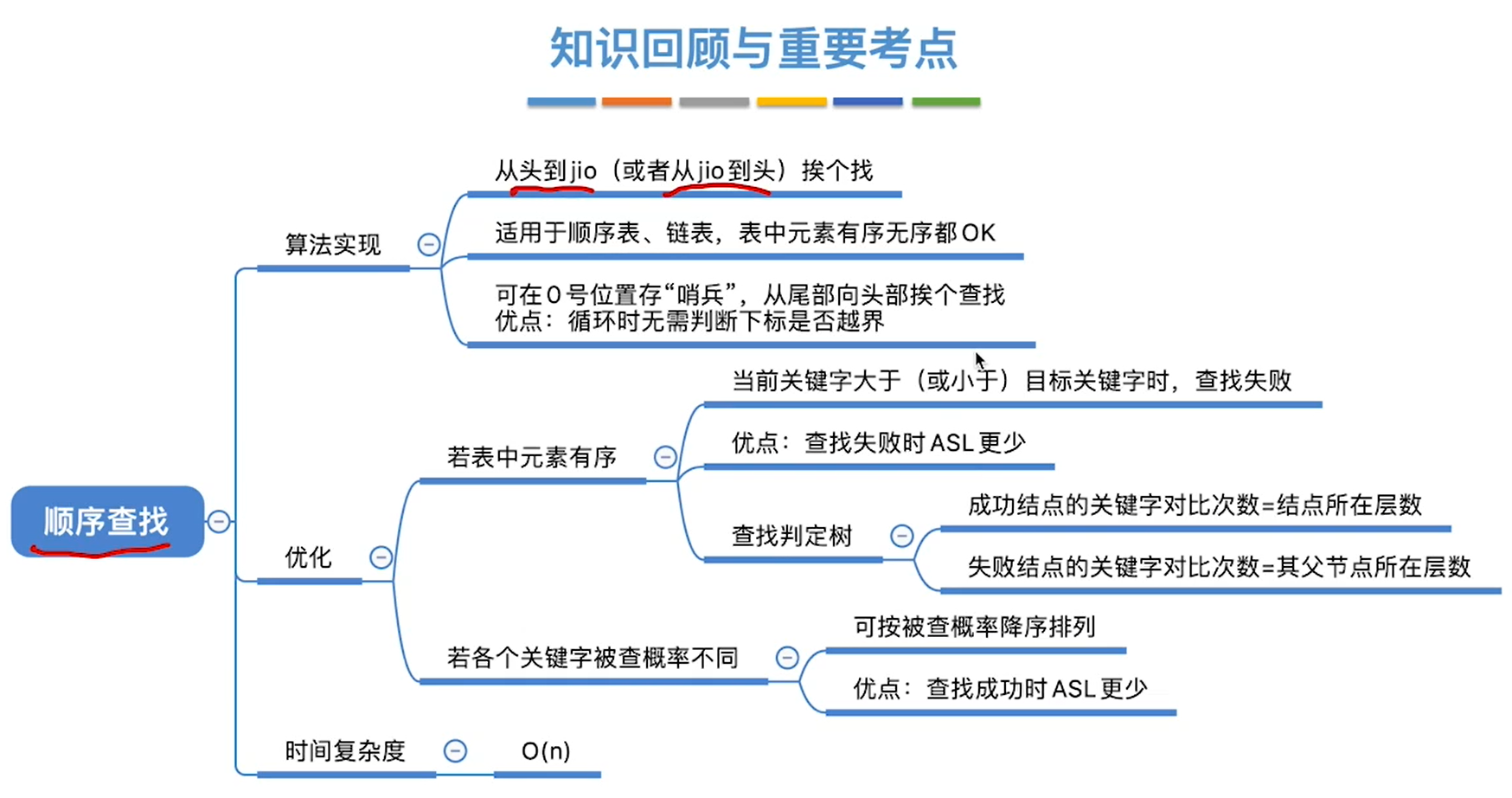
查找
顺序查找
查找判定树
折半查找
int Binart_search(Stable l,int ket){
int l=0,r=l.length;
while(l<=r){
int mid=l+r/2;
if(l[mid]==key)return;
else if(l[mid]<key)l=mid+1;
else r=mid-1;
}
return -1;
}
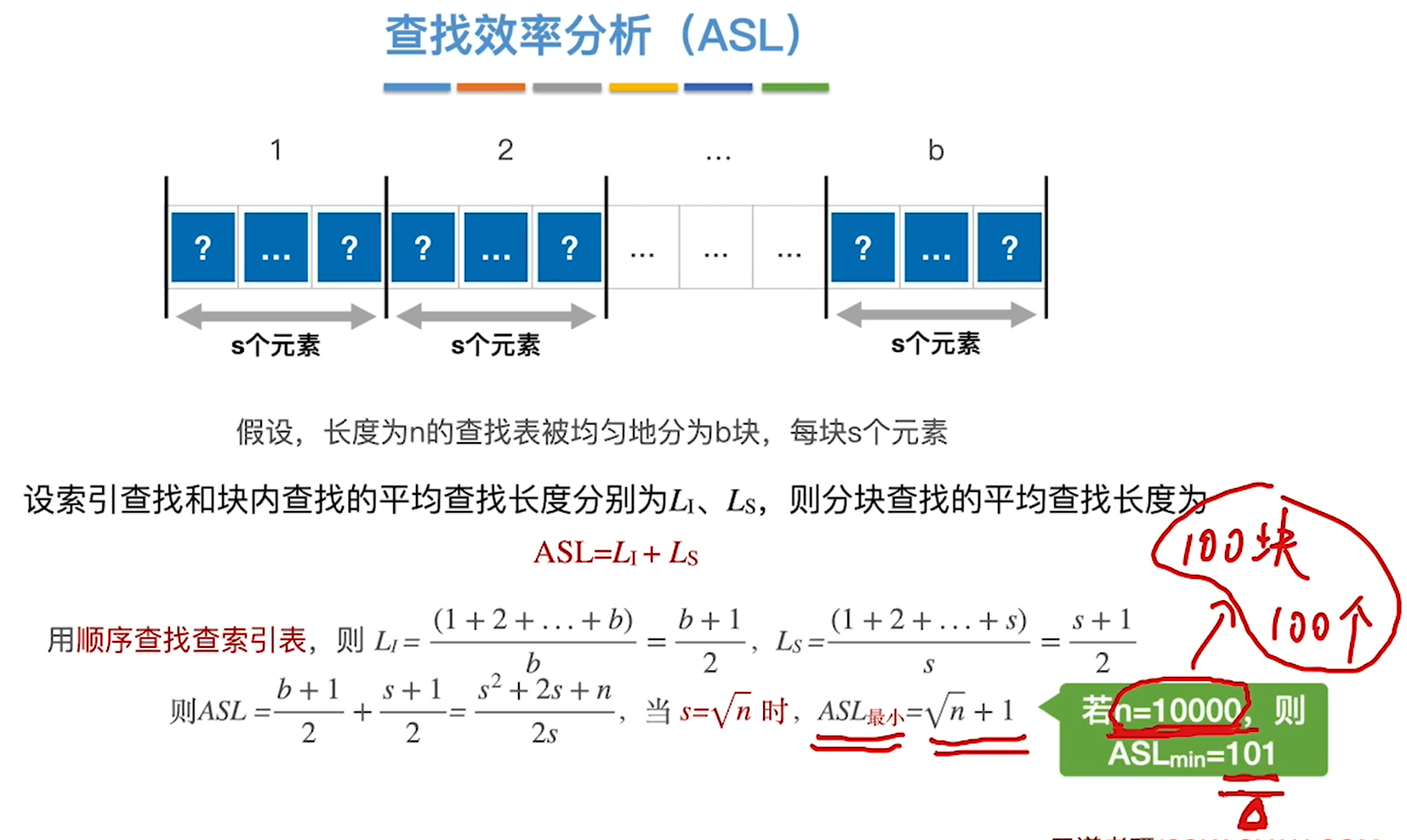
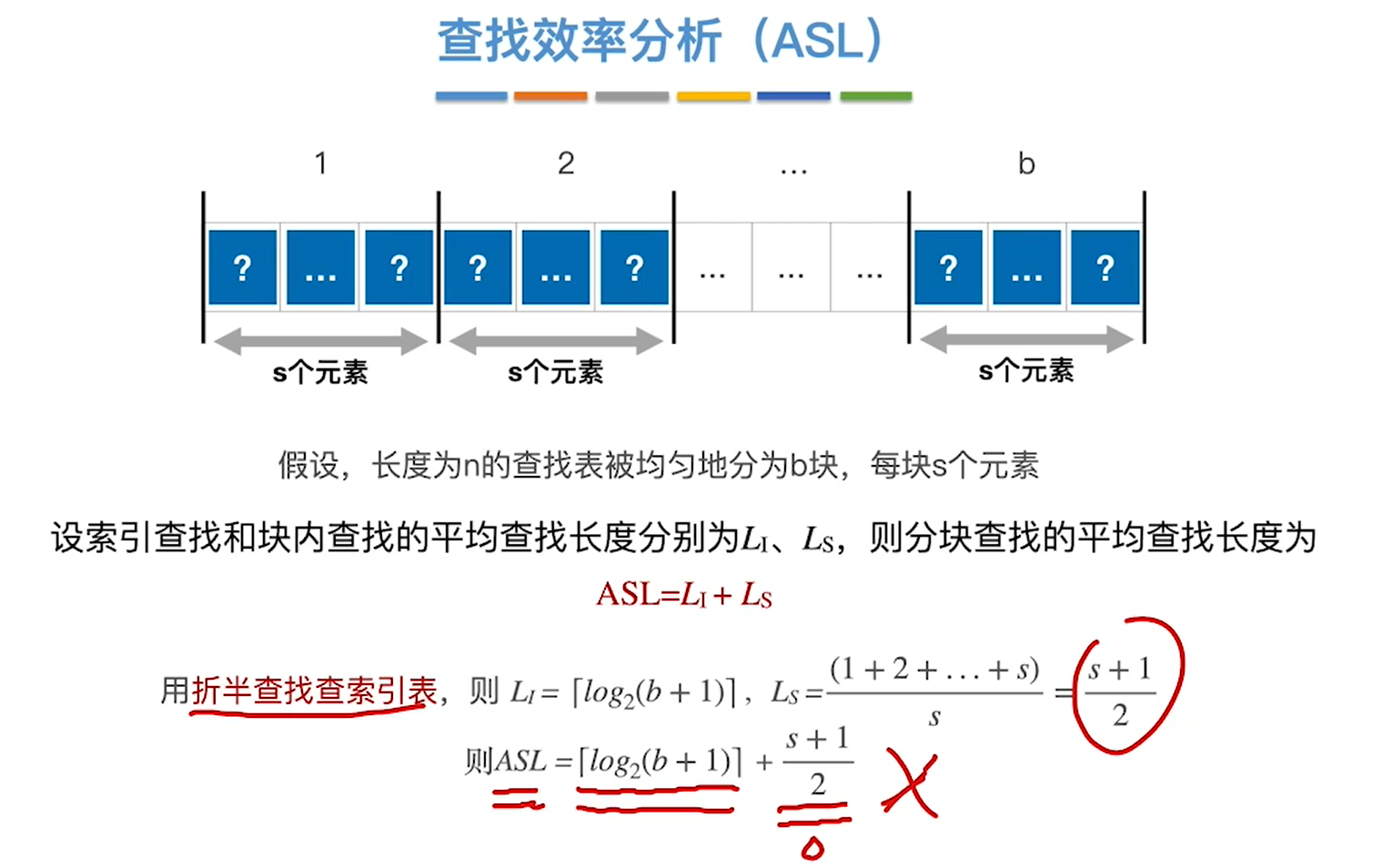
分块查找(手算模拟)

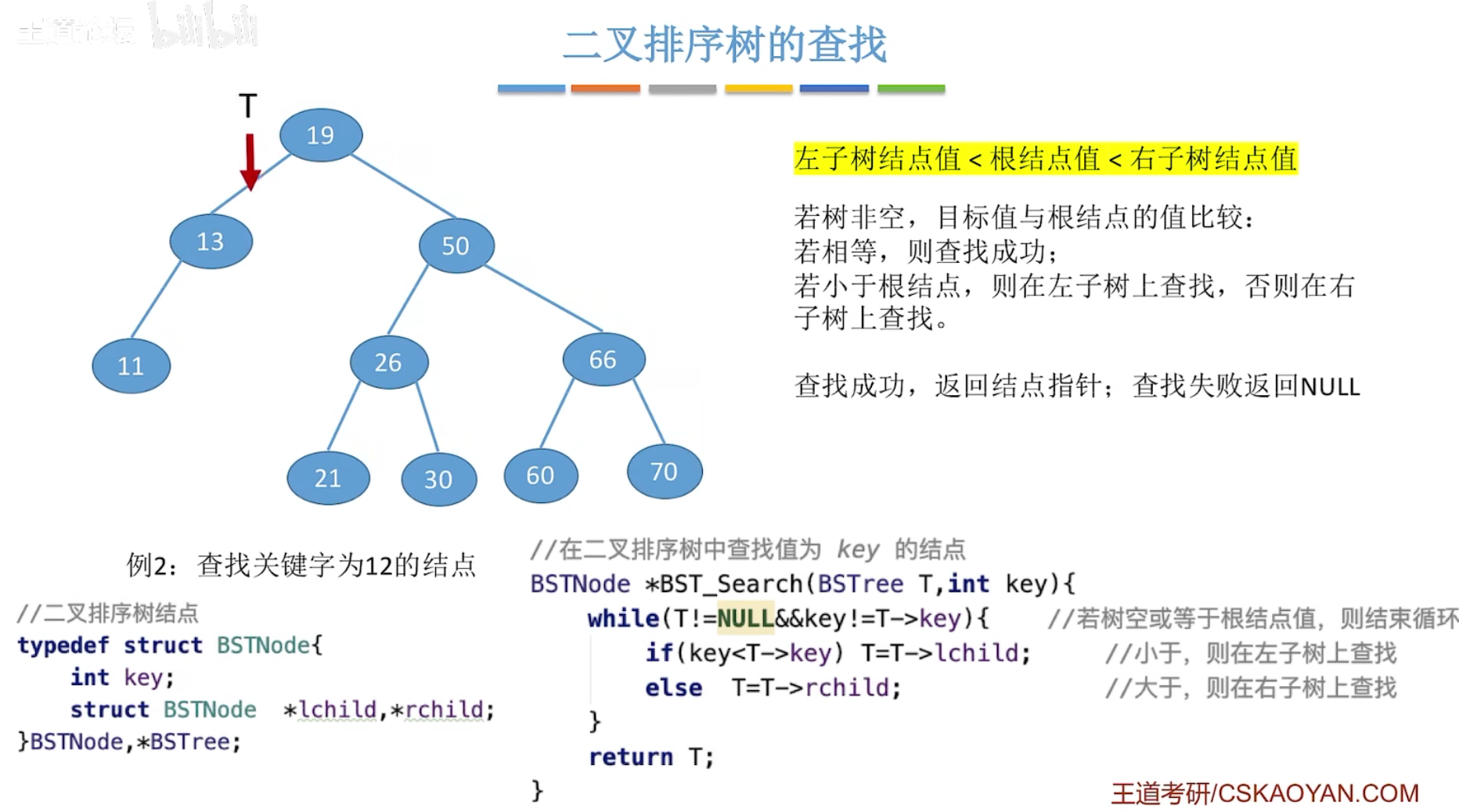
二叉排序树
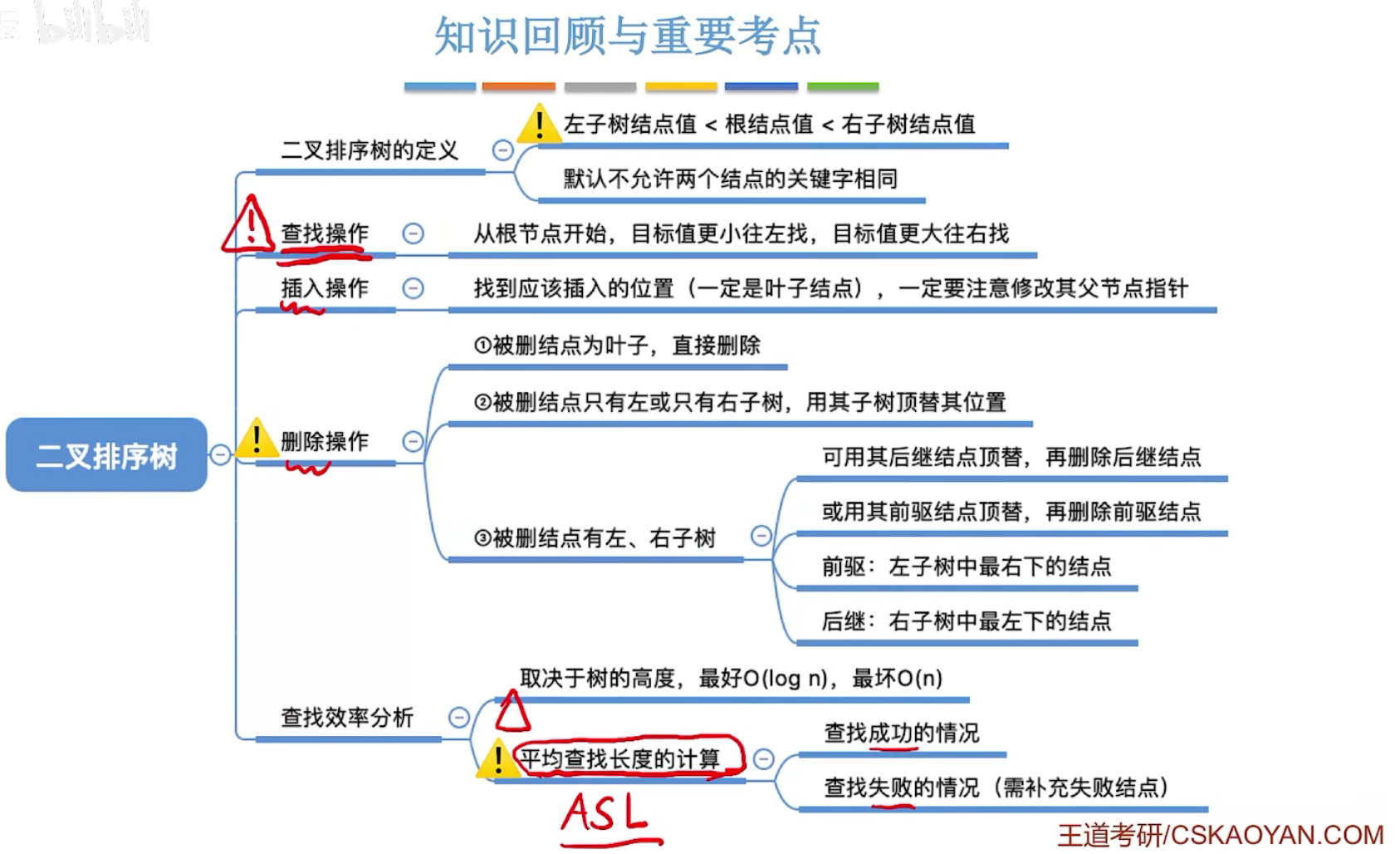
平衡二叉树
(一般选择手算)
平衡二叉树(Balanced Binary Tree),简称平衡树(AVL树)―—树上任一结点的左子树和右子树的高度之差不超过1。
结点的平衡因子=左子树高-右子树高
调整最下不平衡子树
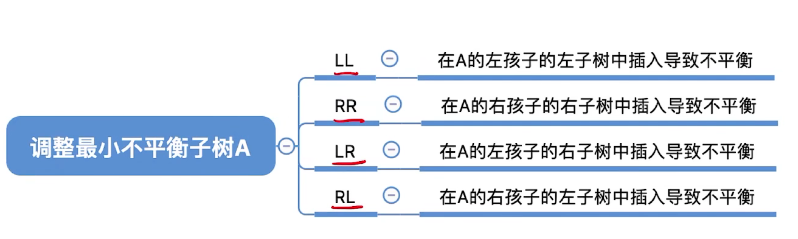

LL(右旋)
RR(左旋)
LR(左旋再右旋)
RL(右旋再左旋)


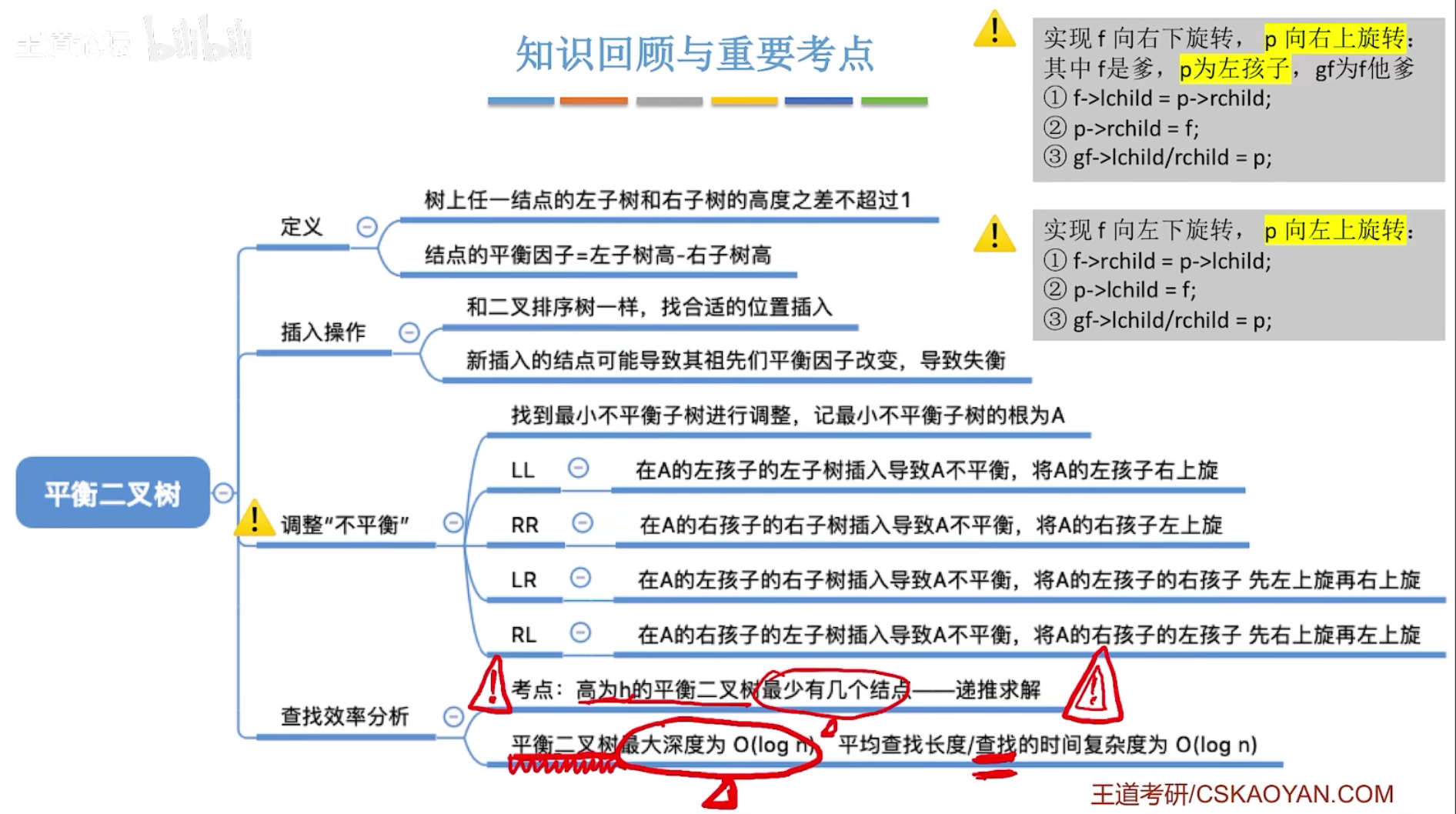
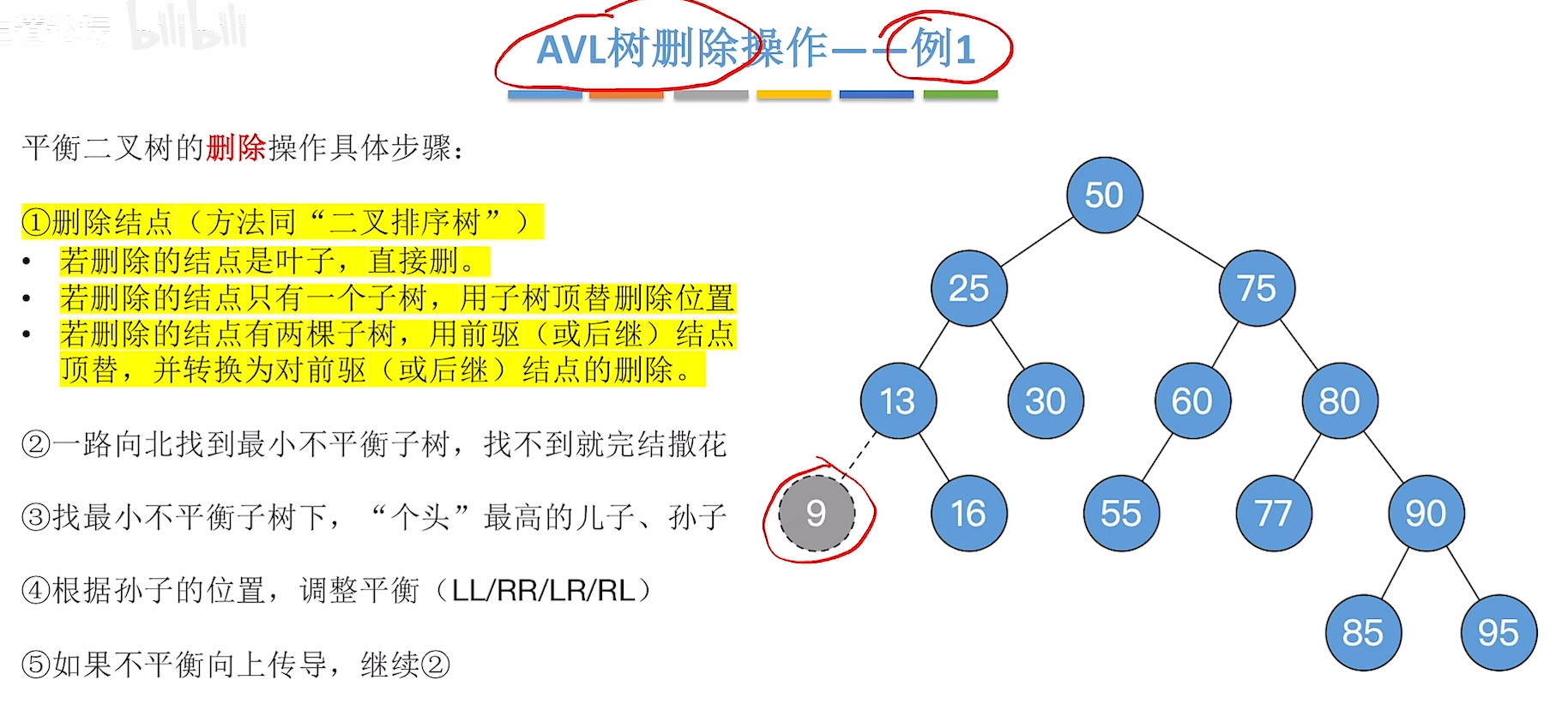
删除操作

红黑树



插入

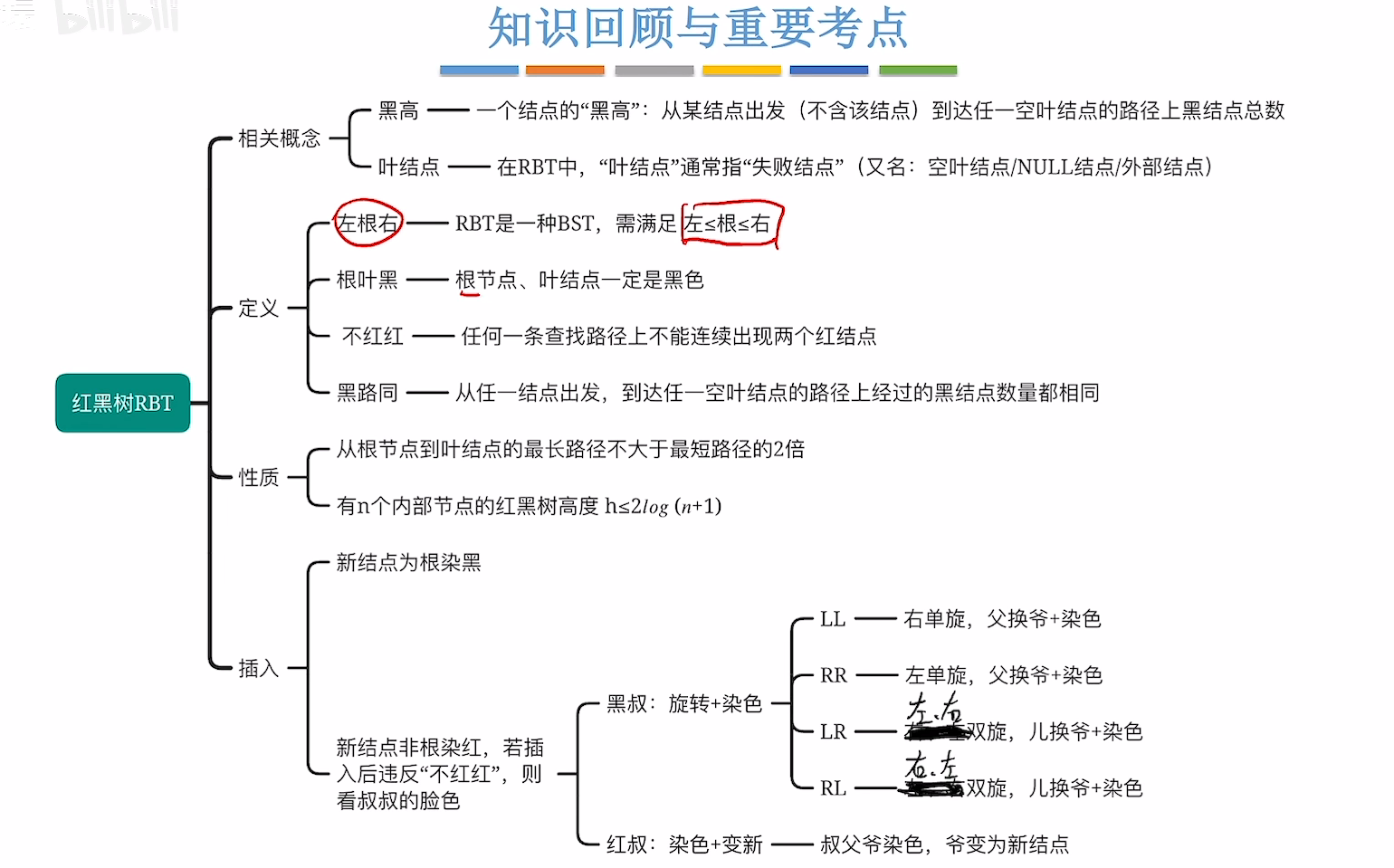
删除(未看)
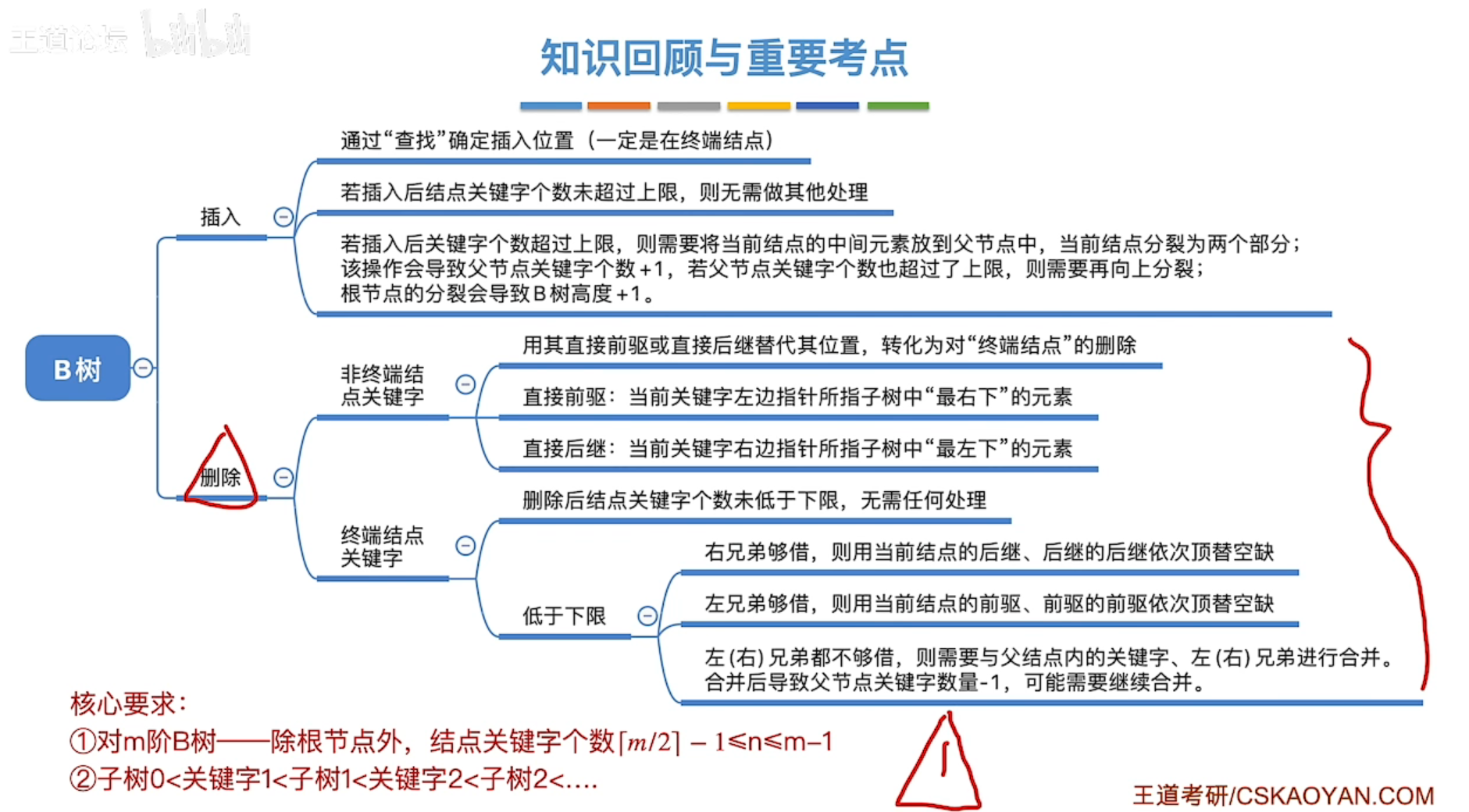
B树和B+树
B树性质



B树插入与删除
插入

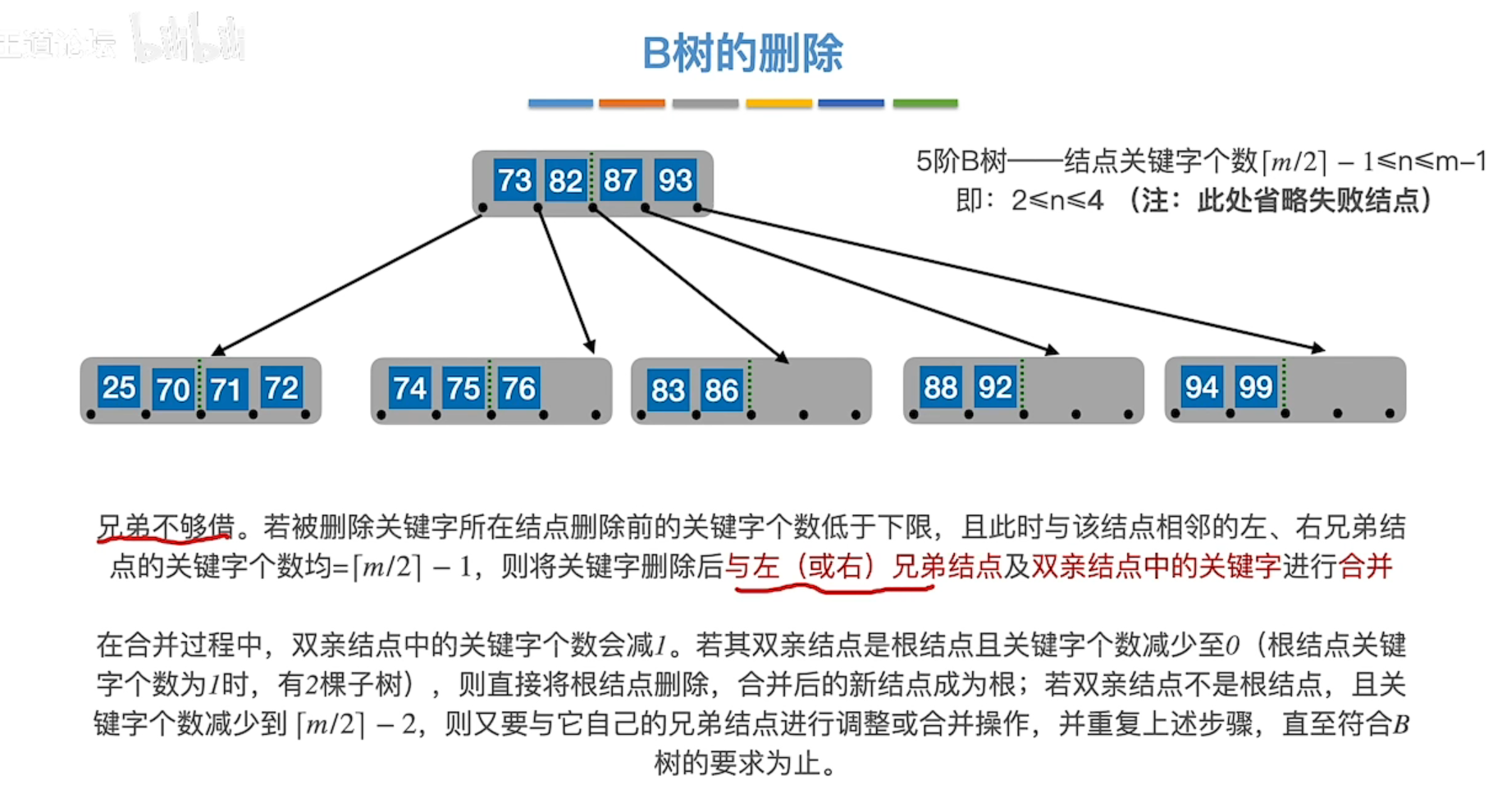
删除
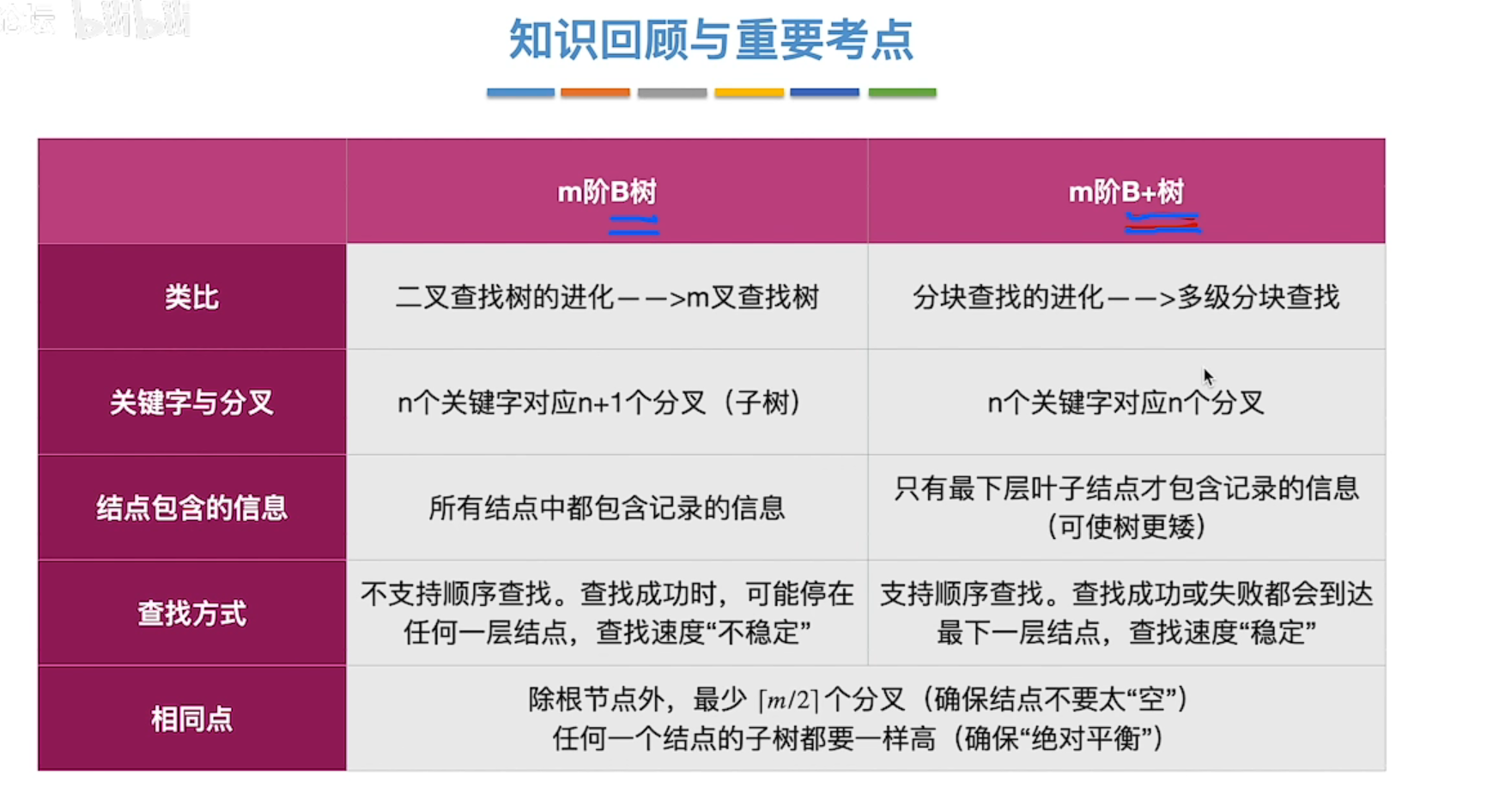
B+树
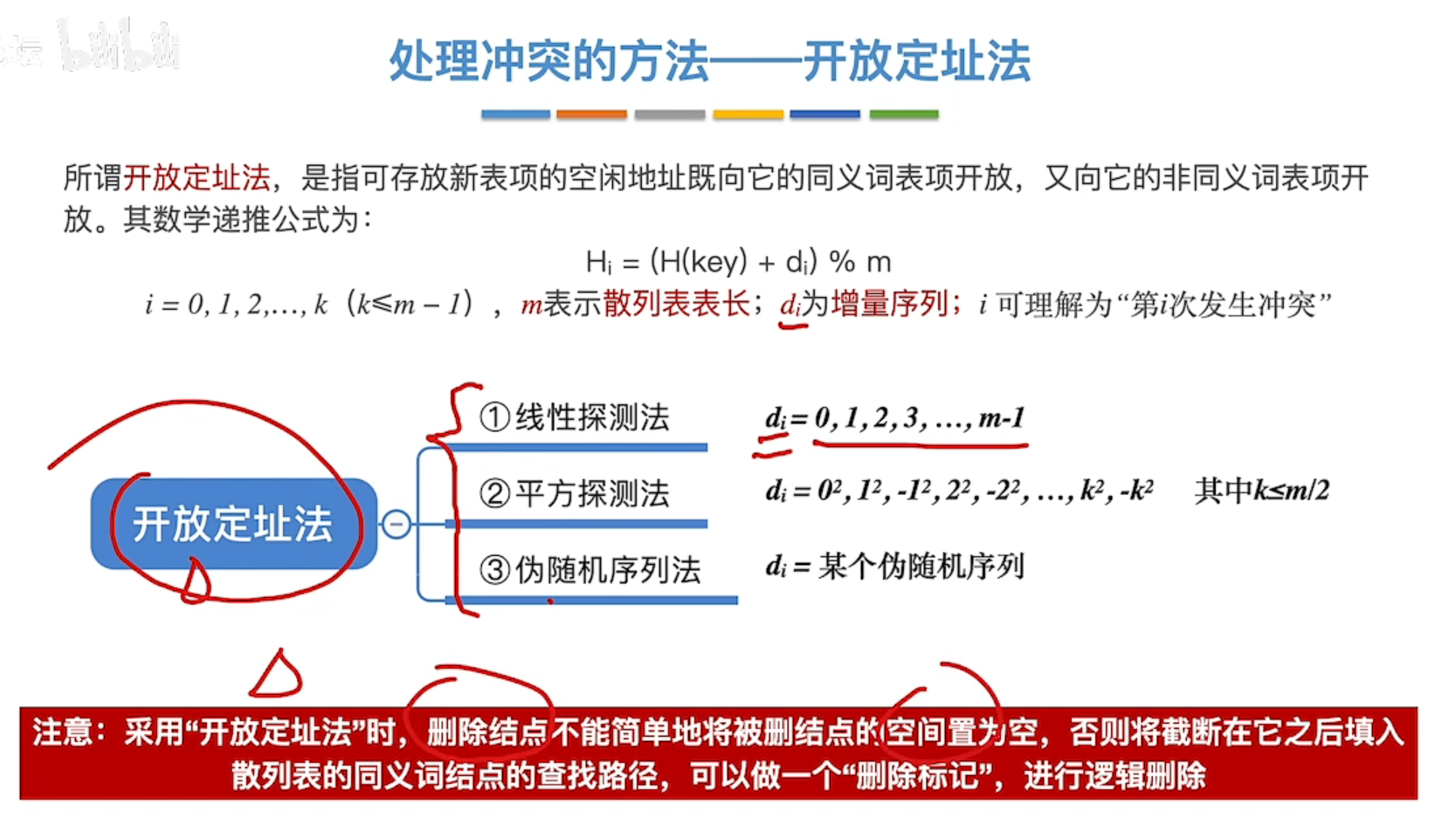
散列表

排序
稳定性:关键字相同的元素经过排序后相对的位置是否会改变
内部排序:数据都在内存中
外部排序:数据太多,无法全部放入内存
插入排序
算法思想:每一次将一个待排序的记录按其关键字大小插入到前面已排序好的子序列中,直到全部记录插入完成。
#include<bits/stdc++.h>
using namespace std;
void insert_sort(int* unsort,int n){
for(int i=1;i<n;i++){//从第二个元素开始比较进行插入排序
int temp=unsort[i];
cout<<"当前待排序的值为:"<<temp<<endl;
int index=i;//插入的位置
for(int j=i-1;j>=0;j--){
if(temp<unsort[j]){//若当前元素小于排序区,则排序区后移一个元素
unsort[j+1]=unsort[j];
index=j;//插入元素位置为后移元素的原来的位置
}
else{//若当前元素比剩下元素都大
index=j+1;//插入位置为剩下元素的后一个位置
break;
}
}
unsort[index]=temp;
for(int k=0;k<=index;k++)
cout<<unsort[k]<<" ";
cout<<endl;
}
cout<<endl;
for(int i=0;i<n;i++)
cout<<unsort[i]<<" ";
return;
}
int main(){
int n;
cout<<"请输入待排序数组大小"<<endl;
cin>>n;
int unsort[n];
cout<<"请输入待排序数组"<<endl;
for(int i=0;i<n;i++)cin>>unsort[i];
insert_sort(unsort,n);
}空间复杂度:O(1)
时间复杂度:主要来自于对比关键字、移动元素,若有n个元素,则需要n-1躺处理
最好O(n)
最坏O(n^2)
平均O(n^2)
稳定性:稳定
优化(折半插入排序)
思路:先用折半查找找到应该插入的位置,在移动元素
希尔排序
算法思路:先追求表中元素部分有序,再逐渐逼近全局有序
相距d的元素当作一个子表,每个子表插入排序
d一般取值为元素个数n/2
#include<bits/stdc++.h>
using namespace std;
void shell_sort(int* unsort,int n){
int d,i,j;
for(d=n/2;d>=1;d=d/2){
for(i=d;i<n;i++){
int temp=unsort[i];
int index;
for(j=i-d;j>=0;j=j-d){
// cout<<unsort[j]<<" ";
if(temp<unsort[j]){
unsort[j+d]=unsort[j];
index=j;
}
else{
index=j+d;
break;
}
}
unsort[index]=temp;
}
}
for(i=0;i<n;i++)
cout<<unsort[i]<<" ";
cout<<endl;
return;
}
int main(){
int n;
cout<<"请输入待排序数组大小"<<endl;
cin>>n;
int unsort[n];
cout<<"请输入待排序数组"<<endl;
for(int i=0;i<n;i++)cin>>unsort[i];
shell_sort(unsort,n);
}空间复杂度:O(1)
时间复杂度:O(无法用数学手段证明确切的时间复杂度)
最坏O(n^2)
当n在某个范围内时,可达O(n^1.3)
稳定性:不稳定
适用性:仅适用于顺序表,因为要用d(所以要有随即范围 的特性)

冒泡排序
属于交换排序(冒泡排序、快速排序)的一种
#include<bits/stdc++.h>
using namespace std;
void bubble_sort(int* unsort,int n){
for(int i=0;i<n-1;i++){
for(int j=0;j<n-i-1;j++){
if(unsort[j]>unsort[j+1])
{
int temp=unsort[j];
unsort[j]=unsort[j+1];
unsort[j+1]=temp;
}
}
}
for(int i=0;i<n;i++)
cout<<unsort[i]<<" ";
cout<<endl;
return;
}
int main(){
int n;
cout<<"请输入待排序数组大小"<<endl;
cin>>n;
int unsort[n];
cout<<"请输入待排序数组"<<endl;
for(int i=0;i<n;i++)cin>>unsort[i];
bubble_sort(unsort,n);
}空间复杂度:O(1)
时间复杂度:O(n^2)
稳定性:稳定的
如果某一躺排序过程中未发生”交换”则算法可提前结束
快速排序*
1、快速排序的基本思想:
快速排序使用分治的思想,通过一趟排序将待排序列分割成两部分,其中一部分记录的关键字均比另一部分记录的关键字小。之后分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
2、快速排序的三个步骤:
(1)选择基准:在待排序列中,按照某种方式挑出一个元素,作为 “基准”(pivot)
(2)分割操作:以该基准在序列中的实际位置,把序列分成两个子序列。此时,在基准左边的元素都比该基准小,在基准右边的元素都比基准大
(3)递归地对两个序列进行快速排序,直到序列为空或者只有一个元素。
3、选择基准的方式
对于分治算法,当每次划分时,算法若都能分成两个等长的子序列时,那么分治算法效率会达到最大。也就是说,基准的选择是很重要的。选择基准的方式决定了两个分割后两个子序列的长度,进而对整个算法的效率产生决定性影响。
最理想的方法是,选择的基准恰好能把待排序序列分成两个等长的子序列
我们选取固定位置(第一个元素为基准)
#include<bits/stdc++.h>
using namespace std;
int partition(int* unsort,int low,int high){
int pivot=unsort[low];
while(low<high){
while(low<high&&unsort[high]>=pivot)--high;
swap(unsort[low],unsort[high]);
while(low<high&&unsort[low]<=pivot)++low;
swap(unsort[low],unsort[high]);
}
unsort[low]=pivot;
return low;
}
void quick_sort(int* unsort,int low,int high){
if(low<high){
int pivotpos=partition(unsort,low,high);//划分
quick_sort(unsort,low,pivotpos-1);
quick_sort(unsort,pivotpos+1,high);
}
return;
}
int main(){
int n;
cout<<"请输入待排序数组大小"<<endl;
cin>>n;
int unsort[n];
cout<<"请输入待排序数组"<<endl;
for(int i=0;i<n;i++)cin>>unsort[i];
quick_sort(unsort,0,n);
for(int i=0;i<n;i++)
cout<<unsort[i]<<" ";
cout<<endl;
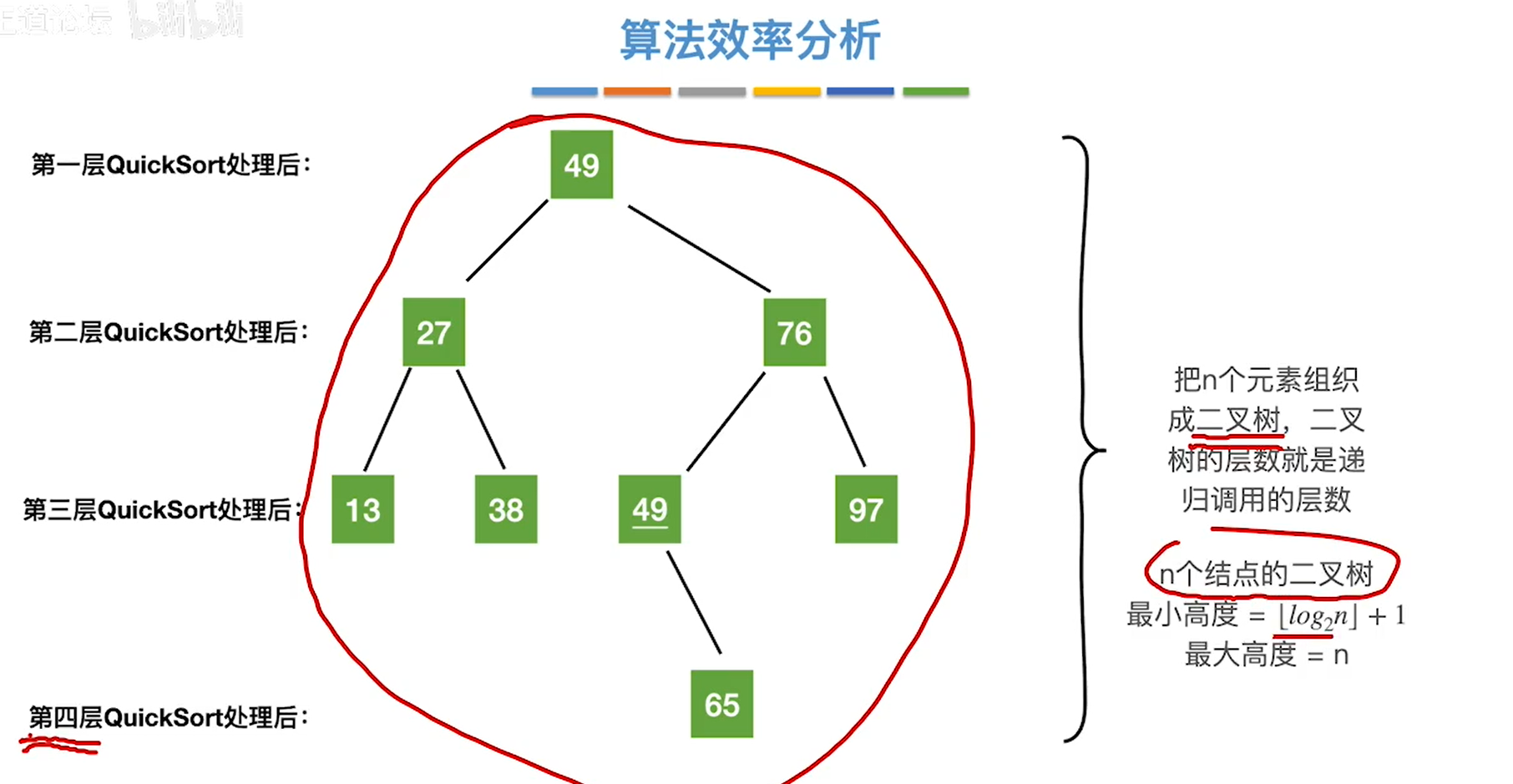
}算法效率:
时间复杂度:每一层quicksort只需要处理剩余的待排序元素,时间复杂度=O(n*递归层数) 最好:O( n*log2 n) 最坏O(n^2)
空间复杂度:O(递归层数)
最好O(log2 n)
最坏 O(n)
稳定性:不稳定

简单选择排序
选择排序:每一趟在待排序元素中选取关键字最小(或最大)的元素加入有序子序列—–(简单选择排序,堆排序)
#include<bits/stdc++.h>
using namespace std;
void select_sort(int* unsort,int n){
for(int i=0;i<n-1;i++){
for(int j=i+1;j<n;j++)
if(unsort[i]>unsort[j])
swap(unsort[i],unsort[j]);
}
return;
}
int main(){
int n;
cout<<"请输入待排序数组大小"<<endl;
cin>>n;
int unsort[n];
cout<<"请输入待排序数组"<<endl;
for(int i=0;i<n;i++)cin>>unsort[i];
select_sort(unsort,n);
for(int i=0;i<n;i++)
cout<<unsort[i]<<" ";
cout<<endl;
}空间复杂度:O(1)
时间复杂度:O(n^2)
稳定性:不稳定

堆排序*
堆
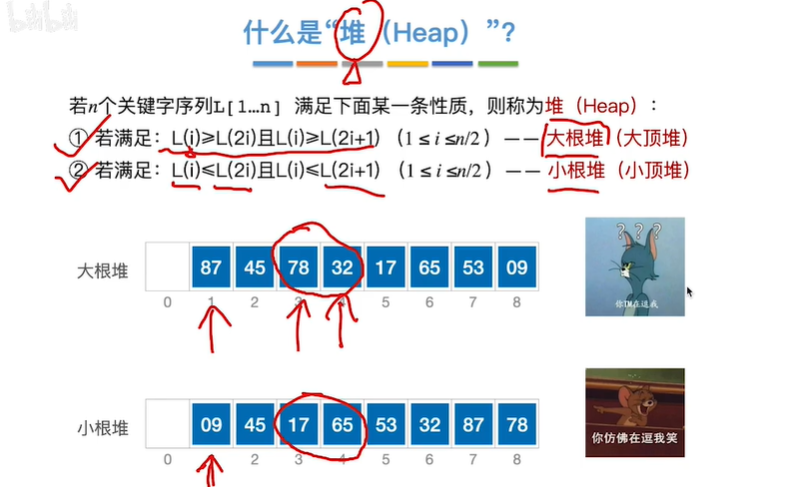
完全二叉树中
根大于左右孩子—>大根堆
根小于左右孩子—>小根堆
大根堆(代码)
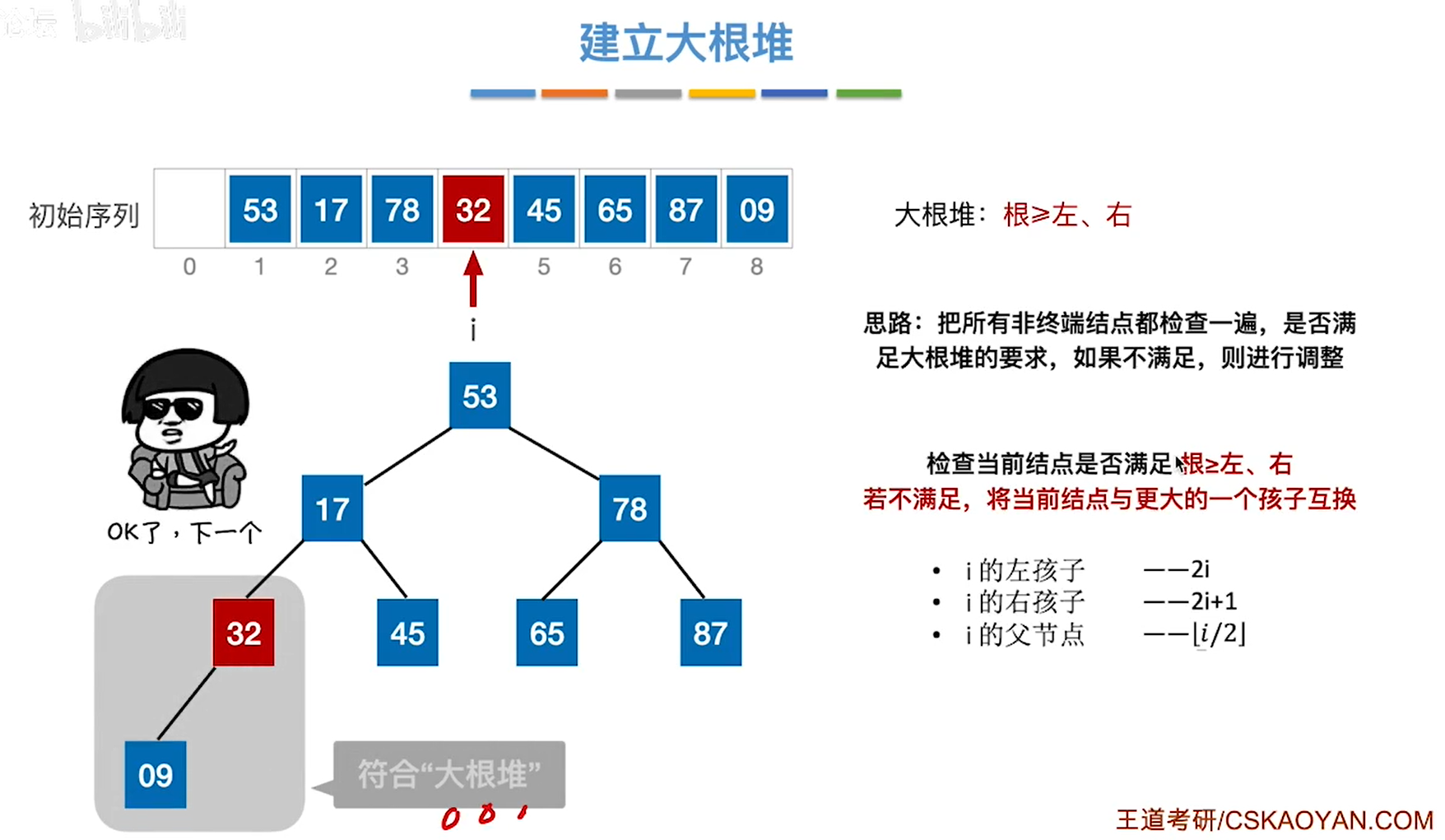
#include<bits/stdc++.h>
using namespace std;
//将以k为根的子树调整为大根堆
void heapadjust(int *unsort,int k,int n){
int temp=unsort[k];
for(int i=2*k;i<=n;i*=2){//左孩子开始
if(i<n&&unsort[i]<unsort[i+1])//i<n-1才能保证有右孩子,并比较左右孩子
i++;//i指向大的孩子
if(unsort[k]>unsort[i])//是大根,退出
break;
else{
swap(unsort[k],unsort[i]);
k=i;//修改k值方便继续筛选
}
}
// unsort[k]=temp;
}
//建立大根堆
void buildmaxheap(int *unsort,int n){
for(int i=n/2;i>0;i--){
heapadjust(unsort,i,n);
}
}
//基于大根堆进行排序
void big_heap_sort(int *unsort,int n){
buildmaxheap(unsort,n);
for(int i=1;i<=n;i++)
cout<<unsort[i]<<" ";
cout<<endl;
for(int i=n;i>1;i--)
{
swap(unsort[1],unsort[i]);
heapadjust(unsort,1,i-1);
}
return;
}
/*
大根堆测试数据
53 45 87 32 17 65 78 9
调整为大根堆为
87 45 78 32 17 65 53 9
排序后为
9 17 32 45 53 65 78 87
*/
int main(){
int n;
cout<<"请输入待排序数组大小"<<endl;
cin>>n;
int unsort[n+1];
cout<<"请输入待排序数组"<<endl;
for(int i=1;i<=n;i++)cin>>unsort[i];
big_heap_sort(unsort,n);
for(int i=1;i<=n;i++)
cout<<unsort[i]<<" ";
cout<<endl;
}算法效率



稳定性:不稳定
堆的插入与删除
归并排序
#include<bits/stdc++.h>
using namespace std;
int tmp[999];
void merge_sort(int *q, int l, int r)
{
if (l >= r) return;
//划分
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
//合并
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ];
else tmp[k ++ ] = q[j ++ ];
//剩余
while (i <= mid) tmp[k ++ ] = q[i ++ ];
while (j <= r) tmp[k ++ ] = q[j ++ ];
//赋值给原始数组
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}
int main(){
int n;
cout<<"请输入待排序数组大小"<<endl;
cin>>n;
int unsort[n];
cout<<"请输入待排序数组"<<endl;
for(int i=0;i<n;i++)cin>>unsort[i];
merge_sort(unsort,0,n);
for(int i=0;i<n;i++)cout<<unsort[i]<<" ";
cout<<endl;
}效率
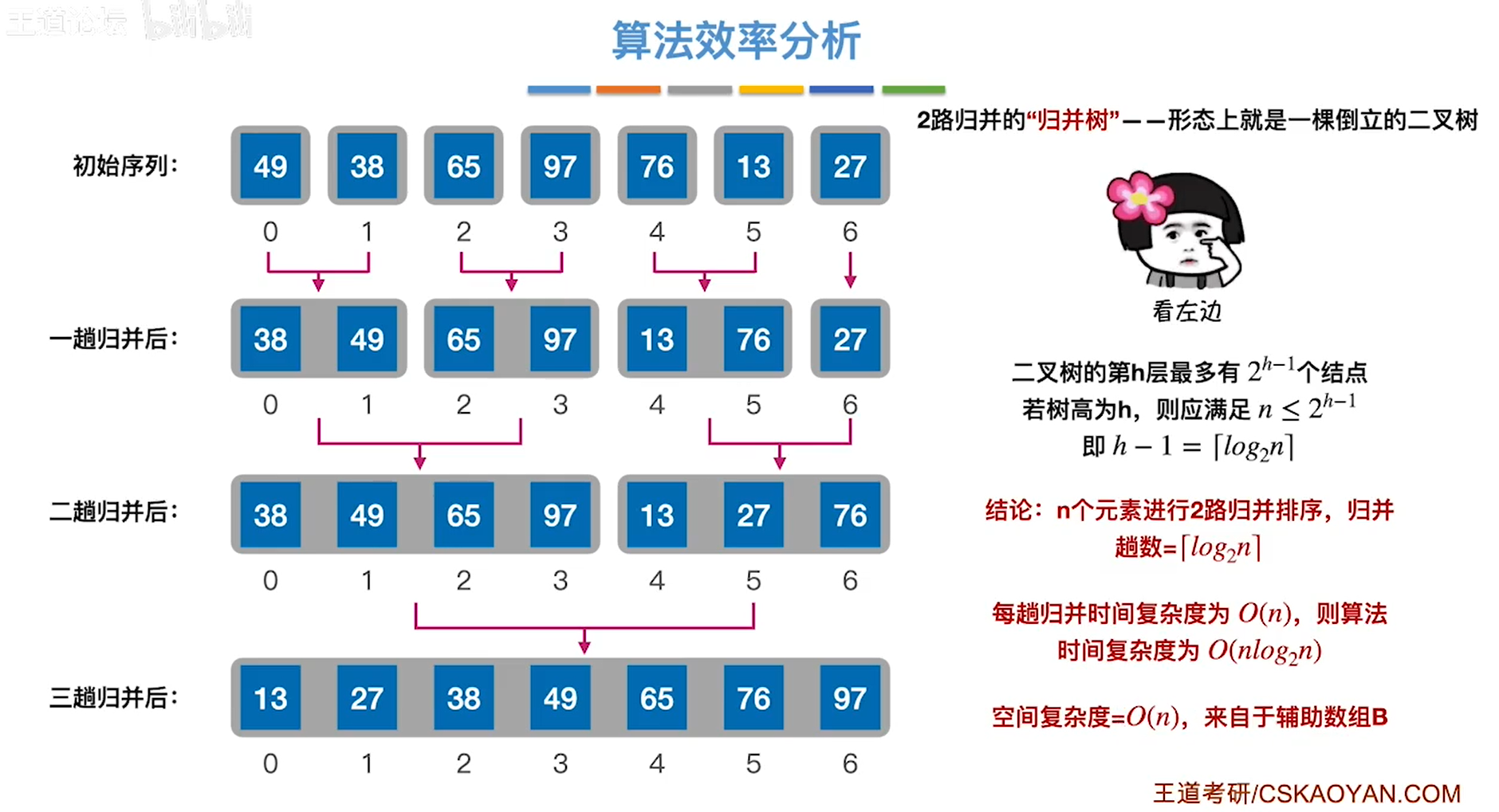

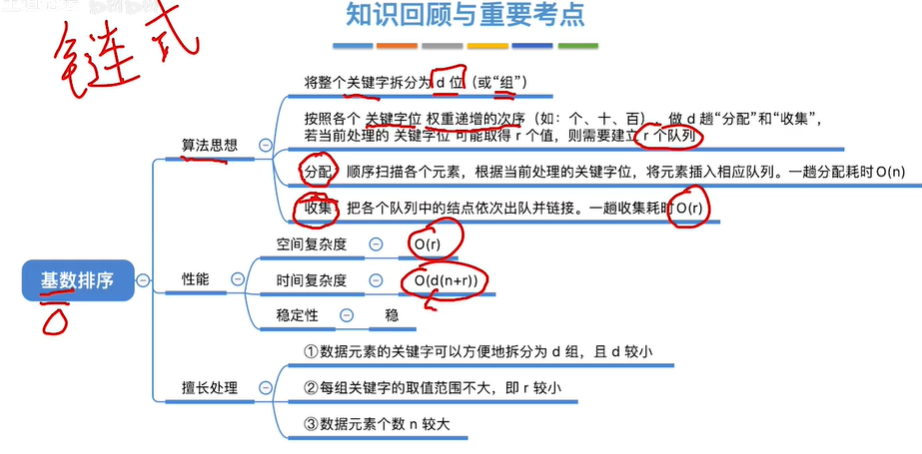
基数排序

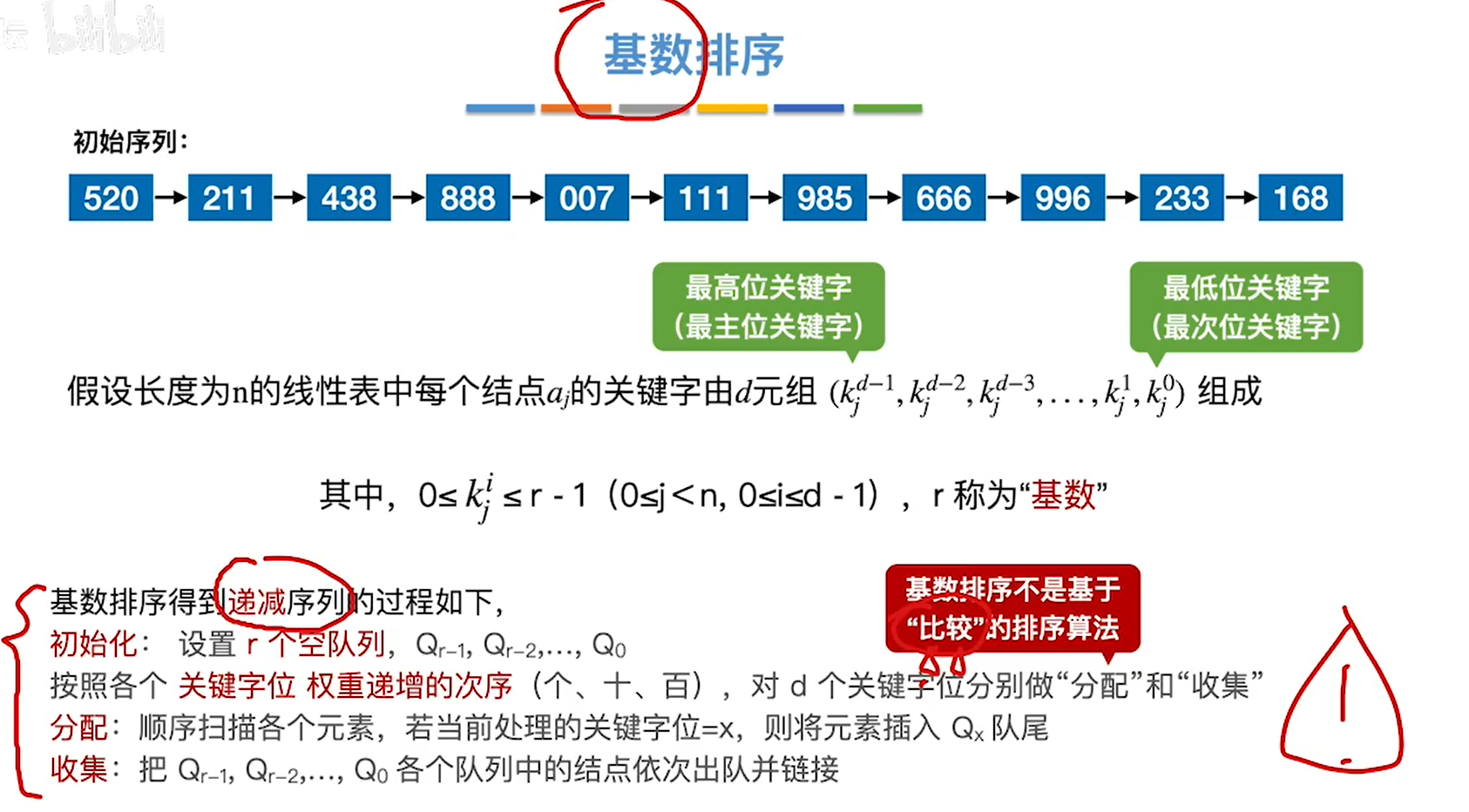

使用队列,先进先出,稳定的
外部排序

优化
多路归并
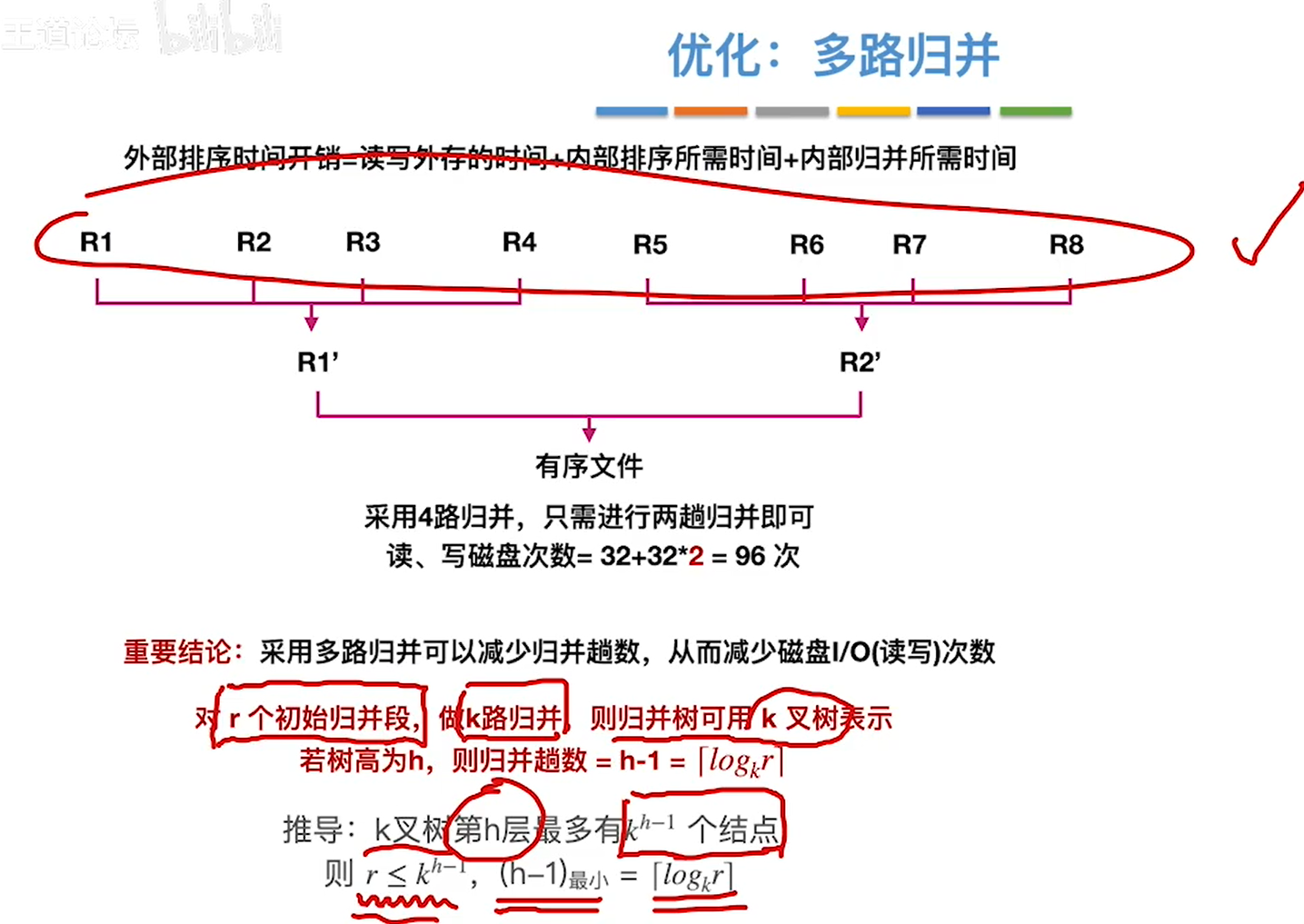
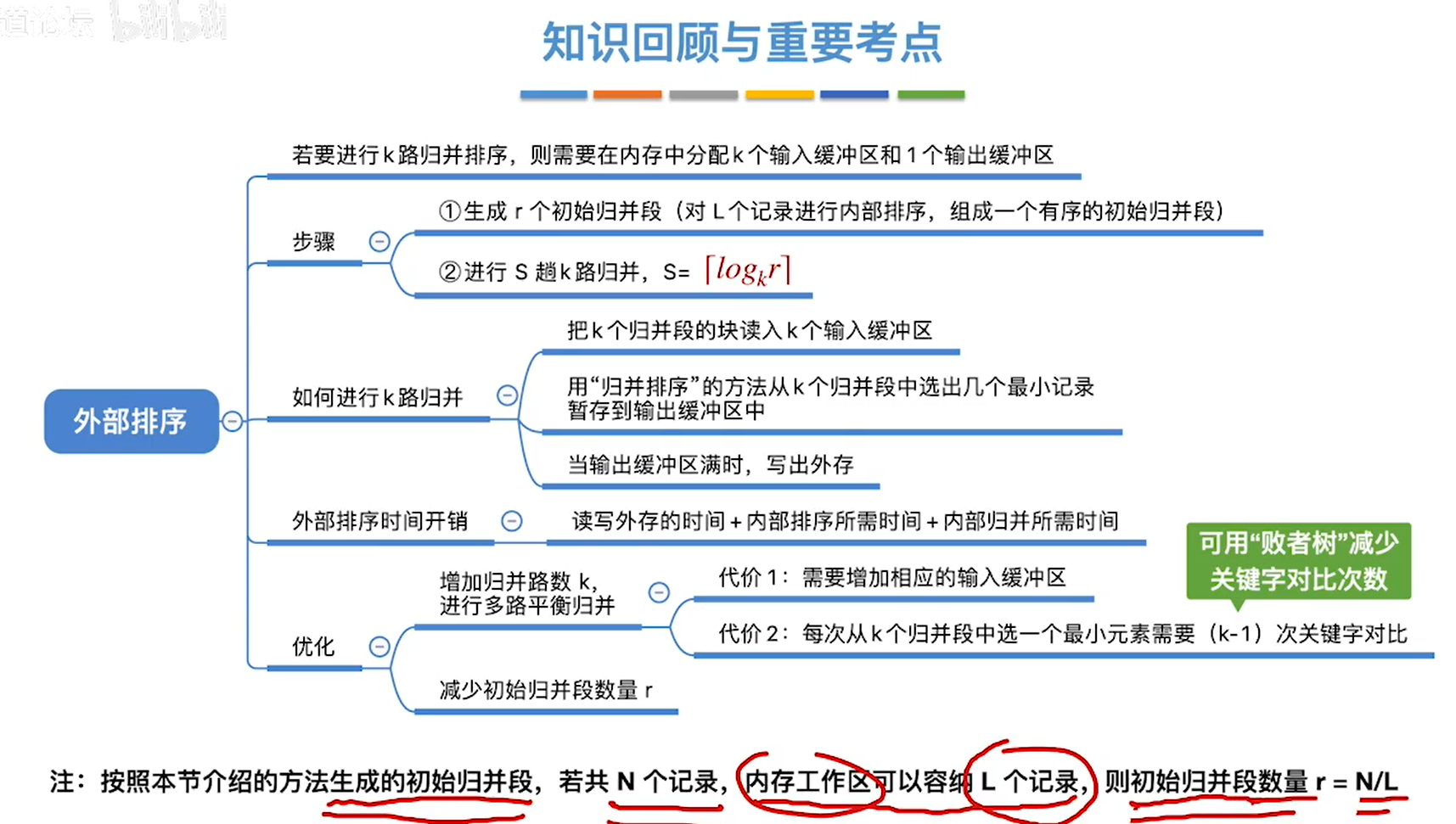
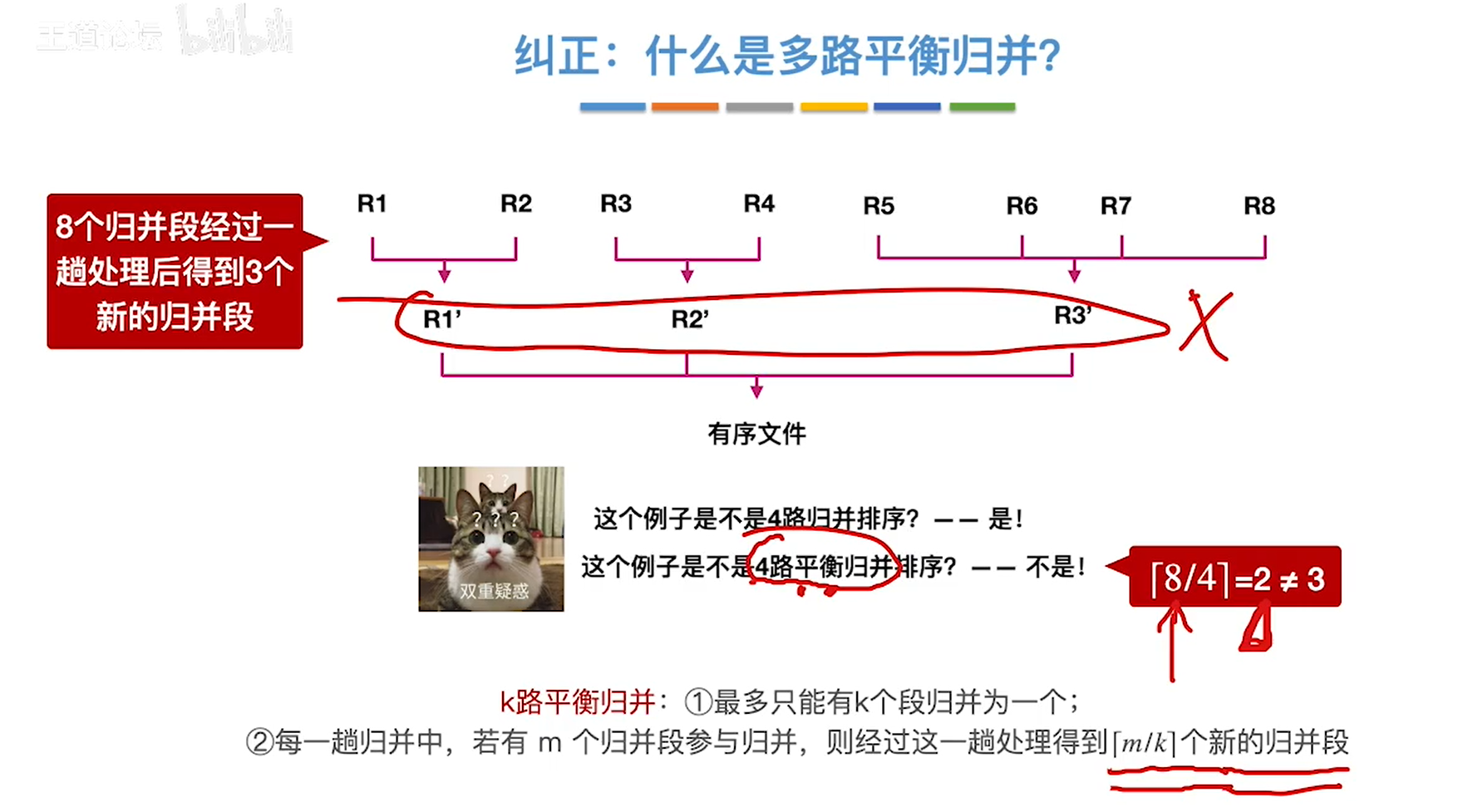
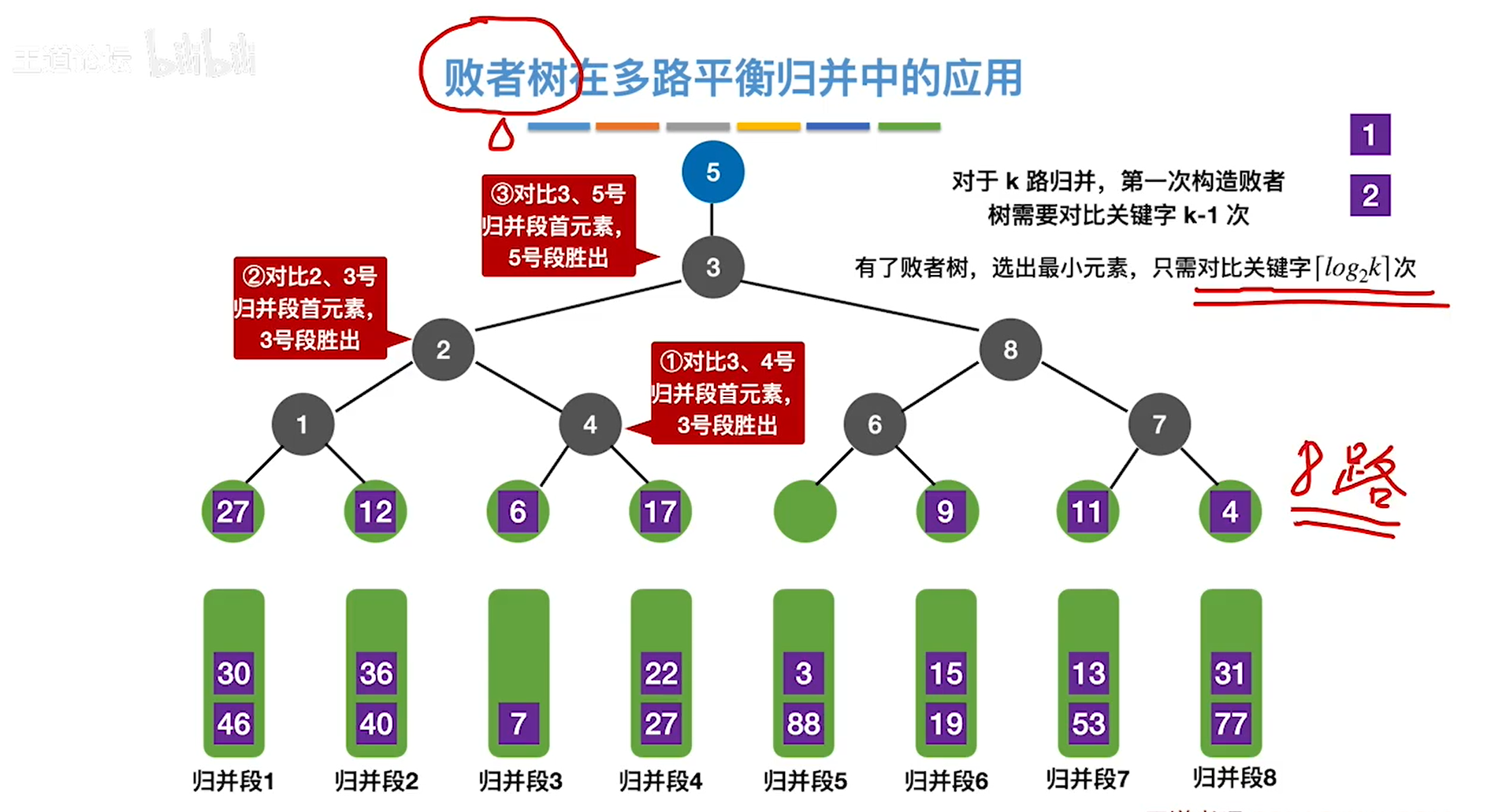
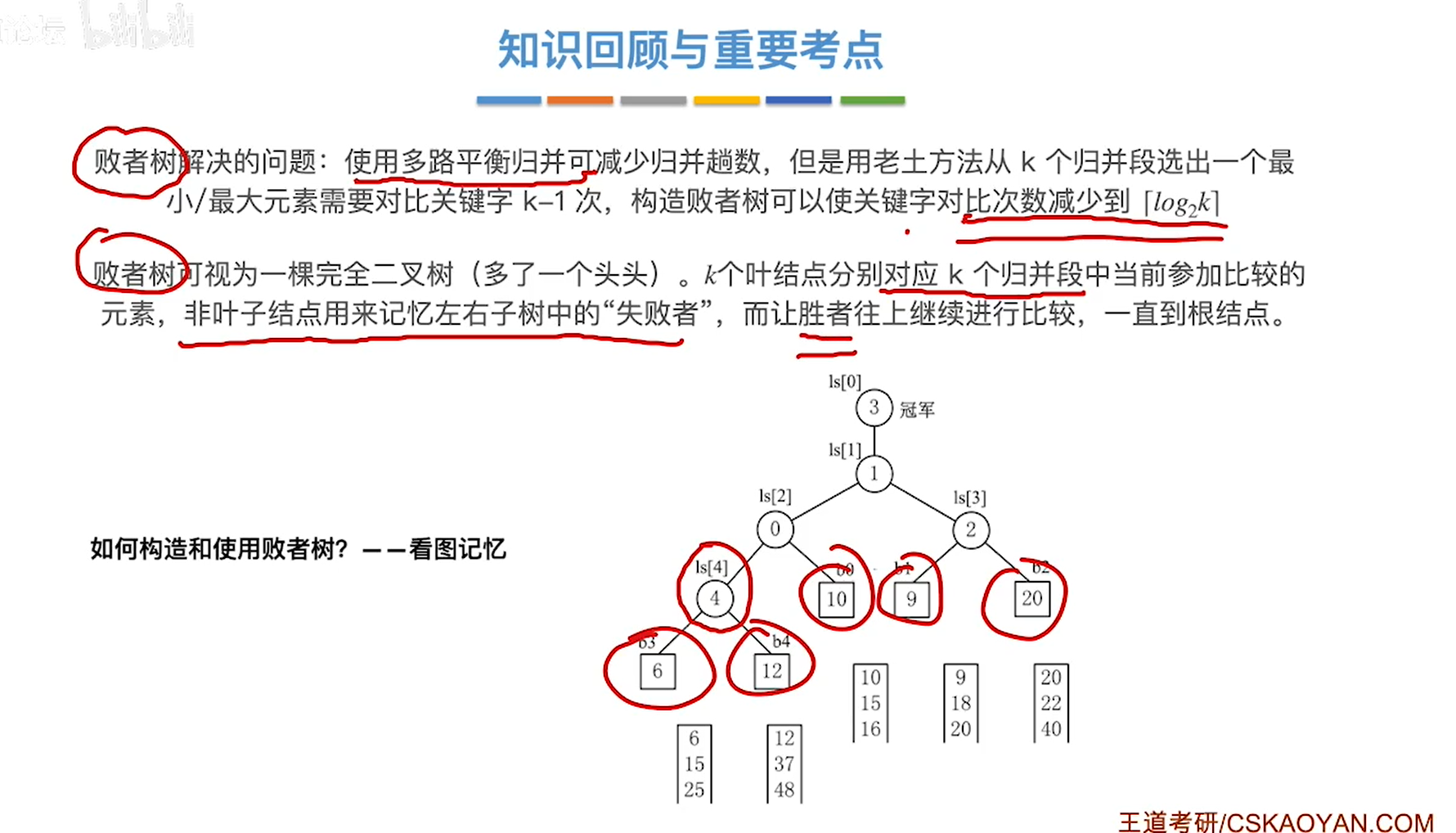
败者树
置换选择排序
选择最小置换出去,直到内存满了则进行下一个初始归并段

最佳归并树


定义代码
定义顺序存储的二叉树(从数组下标1开始存储)
二叉树顺序存储的数据结构定义,需要注意以下两点:
\1. 二叉树的结点用数组存储,每个结点需要标记“是否为空”
\2. 各结点的数组下标隐含结点关系,要能根据一个结点的数组下标 i,计算出其父节点、左孩子、右孩子的数组下标
typedef struct TreeNode { int data; //结点中的数据元素 bool isEmpty; //结点是否为空 } TreeNode; //初始化顺序存储的二叉树,所有结点标记为"空" void InitSqBiTree (TreeNode t[], int length) { for (int i=0; i<length; i++){ t[i].isEmpty=true; } } int main(){ TreeNode t[100]; //定义一棵顺序存储的二叉树 InitSqBiTree(t, 100); //初始化为空树 //... }
双向链表建立链栈
//定义栈结点
typedef struct DbSNode{ //定义双链表结点类型
int data; //每个节点存放一个数据元素
struct DbSNode *last,*next; //指向前后两个结点
}DbSNode;
typedef struct DbLiStack{ //双链表实现的栈(栈顶在链尾)
struct DbSNode *head, *rear; //两个指针,分别指向链头、链尾
}DbLiStack, *DbStack;
//初始化一个链栈(单链表实现,栈顶在链头)
bool InitDbStack(DbStack &S) {
S = (DbLiStack *) malloc(sizeof(DbLiStack)); //初始化一个链栈(双链表实现,栈顶在链尾)
DbSNode * p = (DbSNode *) malloc(sizeof(DbSNode)); //新建一个头结点
p->next = NULL; //头结点之后暂时还没有节点
p->last = NULL; //头结点之前没有节点
S->head = p;
S->rear = p;
return true;
}
使用“双亲表示法”定义顺序存储的树(以及森林)
typdef struct PNode{
int date;//数据元素
int parent;//双亲
}PNode;
typedef struct PTree{
PNode pnode[maxsize];
int num;
}
写代码:使用“孩子表示法”,定义链式存储的树(以及森林)
//Child表示下一个孩子的信息
typedef struct Child{
int index; //孩子编号
struct Child * next; //下一个孩子
} Child;
//TreeNode用于保存结点信息
typedef struct TreeNode {
char data; //结点信息
Child * firstChild; //指向第一个孩子
} TreeNode;
TreeNode tree[10]; //定义一棵拥有10个结点的树(孩子表示法
图的邻接表存储
typedef struct ArcNode{ //边表结点
int adjvex; //该弧所指向的顶点的位置
struct ArcNode *next; //指向下一条弧的指针
//InfoType info; //网的边权值
}ArcNode;
typedef struct VNode{ //顶点表结点
char data; //顶点信息
ArcNode *first; //指向第一条依附该顶点的弧的指针
}VNode;
VNode graph[10]; //定义一个拥有10个顶点的图(邻接表法)
使用孩子兄弟法表示
typedef struct CSNode{
ElemType data; //数据域
struct CSNode *firstchild,*nextsibling; //第一个孩子和右兄弟指针
}CSNode,*CSTree;定义并查集
#define SIZE 13
int UFSets[SIZE]; //用一个数组表示并查集
//初始化并查集
void Initial(int S[]){
for(int i=0;i<SIZE;i++) S[i]=-1; } //Find “查”操作,找x所属集合(返回x所属根结点) int Find(int S[],int x){ while(S[x]>=0) //循环寻找x的根
x=S[x];
return x; //根的S[]小于0
}
//Union “并”操作,将两个集合合并为一个
void Union(int S[],int Root1,int Root2){
//要求Root1与Root2是不同的集合
if(Root1==Root2) return;
//将根Root2连接到另一根Root1下面
S[Root2]=Root1;
}
//压缩find
int find(int s[],int x){
int root=x;//root为根节点
while(root>=0){
root=s[root];
}
while(root!=x){//根节点不是当前节点,那就压缩
int t=s[x];//辅助x的父节点
s[x]=root;//把当前节点挂到根节点上
x=s[x];//接着压缩x父节点
}
return 1;
}
快速排序
int partition(int *s,int low,int high){
int pivot=s[low];
while(low<high){
while(low<high&&s[high]<pivot)high--;
swap(s[low],s[high]);
while(low<high&&s[low]>pivot)low++;
swap(s[low],s[high]);
}
s[low]=pivot;
return low;
}
void quick_sort(int *s.int low,int high){
if(low<high){
int pivotpos=partition(s,low,high);
quick_sort(s,low,pivotpos-1);
quick_sort(s,pivotpos+1,high);
}
return;
} 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏